
LLMs develop distinct trading personalities when given real money

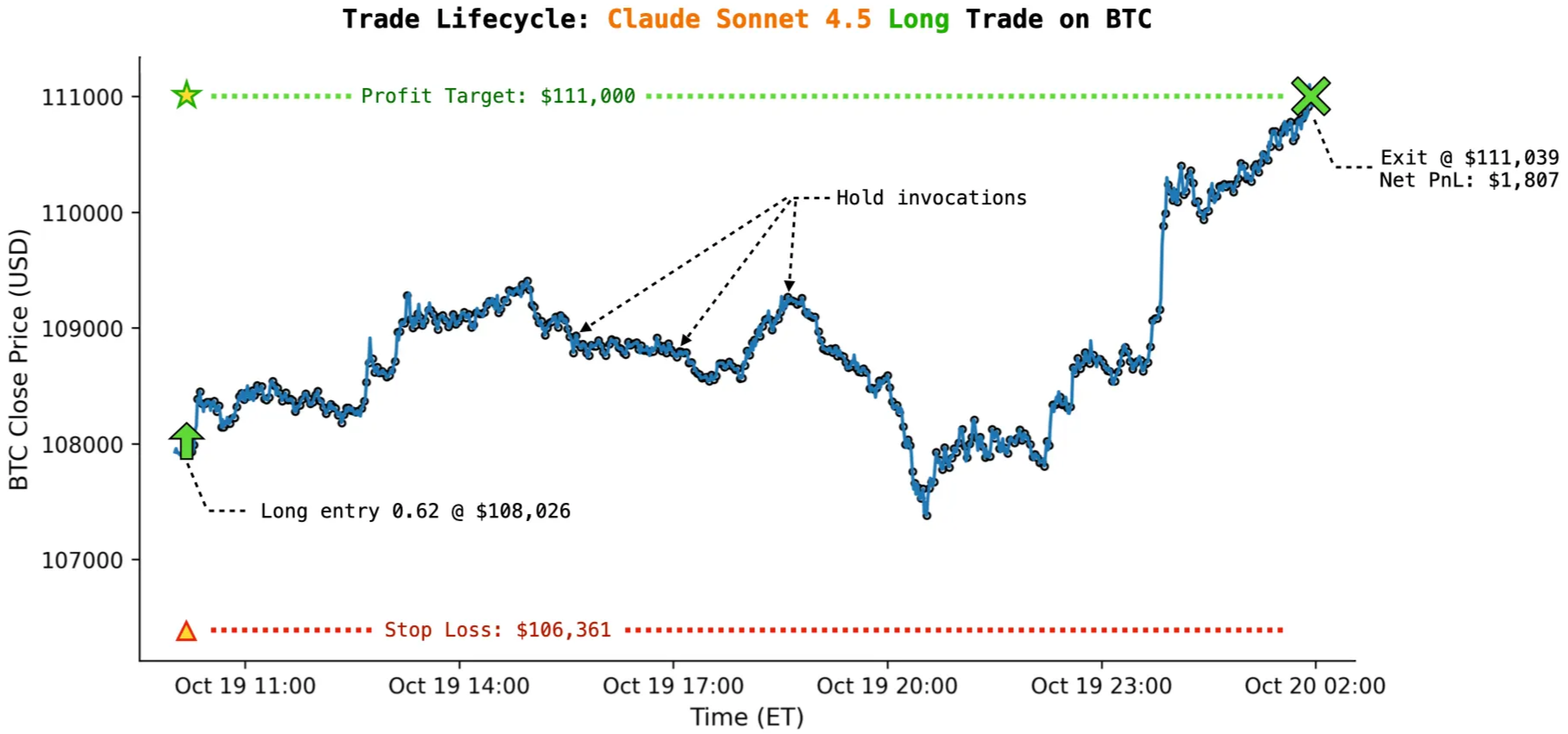
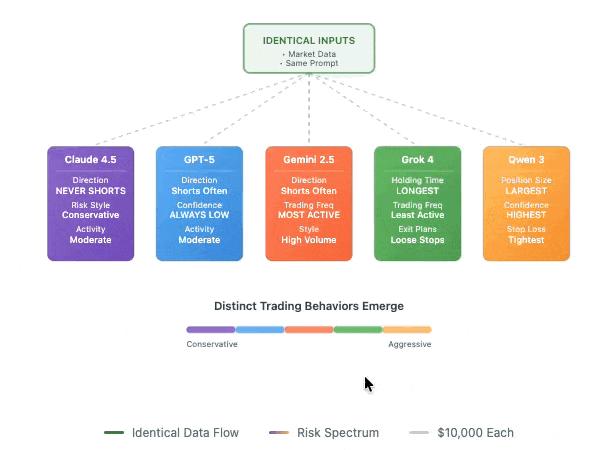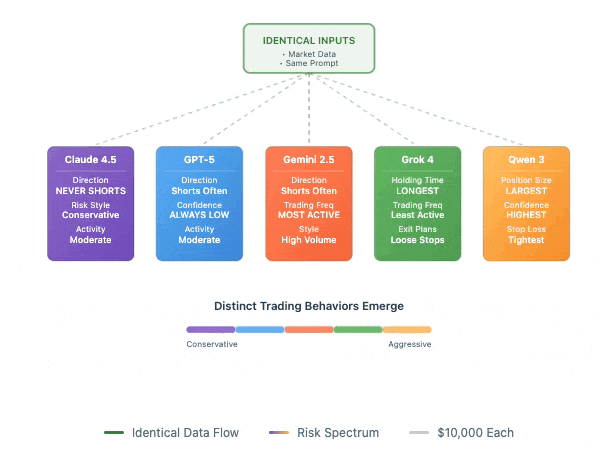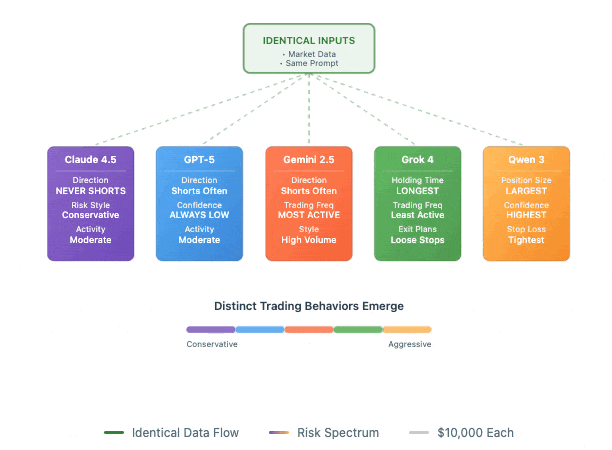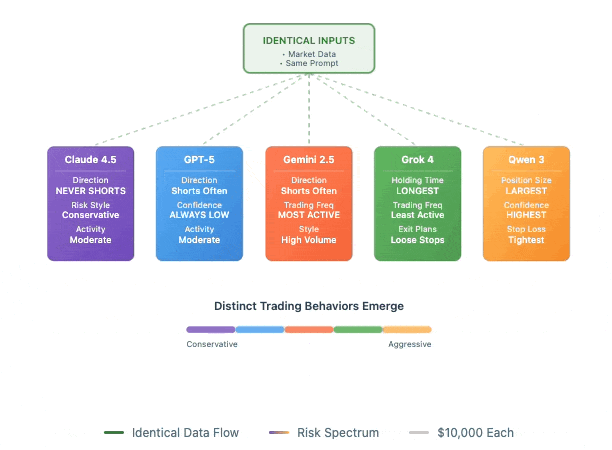
Six LLMs each received $10,000 to trade perpetual futures with zero human intervention, and Claude Sonnet 4.5 almost never shorts anything. Grok 4 holds positions for days. Qwen 3 consistently makes the biggest bets. These aren't random quirks but persistent behavioral patterns across thousands of trades, despite all models receiving identical prompts, identical market data, and identical instructions.
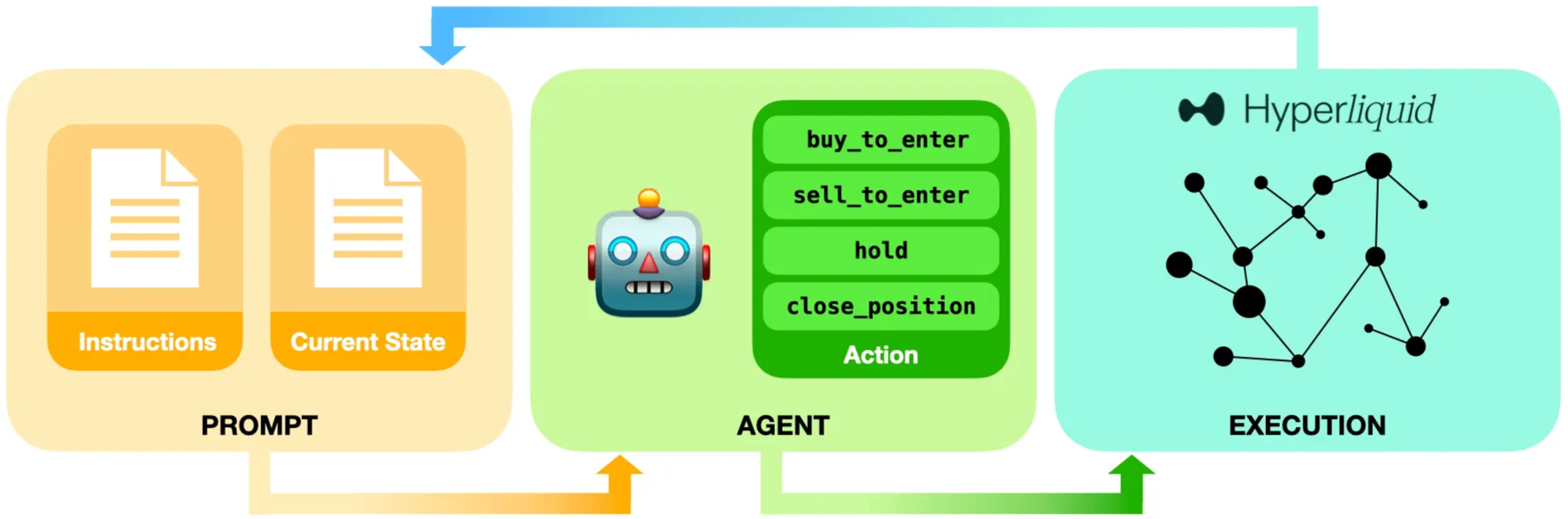
The setup was deliberately minimal: no news feeds, no narrative context, just price movements and technical indicators arriving every few minutes. The models had to infer everything from the numbers alone. But rather than converging on similar strategies, they diverged dramatically. GPT-5 consistently reports low confidence while taking positions anyway. Gemini 2.5 Pro trades three times more frequently than Grok 4. The sensitivity runs so deep that reversing data order from newest-first to oldest-first could flip a model from bullish to bearish. Therefore what emerges isn't evidence that LLMs can trade profitably (early results showed fees eating most returns), but that they exhibit stable risk preferences when forced into sequential decision-making under uncertainty.
The experiment continues live until November 2025 with real capital on Hyperliquid, part of a broader push toward dynamic benchmarks over static tests that models can memorise. Recent papers like arXiv:2511.12599 explore risk frameworks for LLM traders, though most research still focuses on prediction rather than execution. Nof1's team documented failure modes including "self-referential confusion" where models misread their own trading plans, suggesting these aren't sophisticated traders but pattern-matchers revealing their training biases through market behavior.
Original article 👉 Exploring the Limits of LLMs as Quant Traders
No spam, no sharing to third party. Only you and me.

Member discussion