
Reasoning LLMs are wanderers rather than systematic explorers

It turns out that when we ask reasoning capable models such as the latest LLMs (GPT-5 family, Claude Opus and successors, Gemini 1.5 Pro etc.) to think through problems, they often behave like explorers wandering aimlessly rather than systematic searchers. The paper titled Reasoning LLMs are Wandering Solution Explorers formalises what it means to systematically probe a solution space (valid transitions, reaching a goal, no wasted states), but then shows that these models frequently deviate by skipping necessary states, revisiting old ones, hallucinating conclusions or making invalid transitions. This approach can still look effective on simple tasks, but once the solution space grows in depth or complexity, the weaknesses surface. Therefore the authors argue that large models are often wandering rather than reasoning, but their mistakes stay hidden on shallow problems.
The upshot is that a wanderer can stumble into answers on small search spaces, but that same behaviour collapses when the task becomes deep or requires strict structure. The authors show mathematically and empirically that shallow success can disguise systemic flaws, but deeper problems expose the lack of disciplined search. Therefore performance plateaus for complex reasoning cannot simply be fixed by adding more tokens or more compute, but instead require changes in how we guide or constrain the reasoning process.
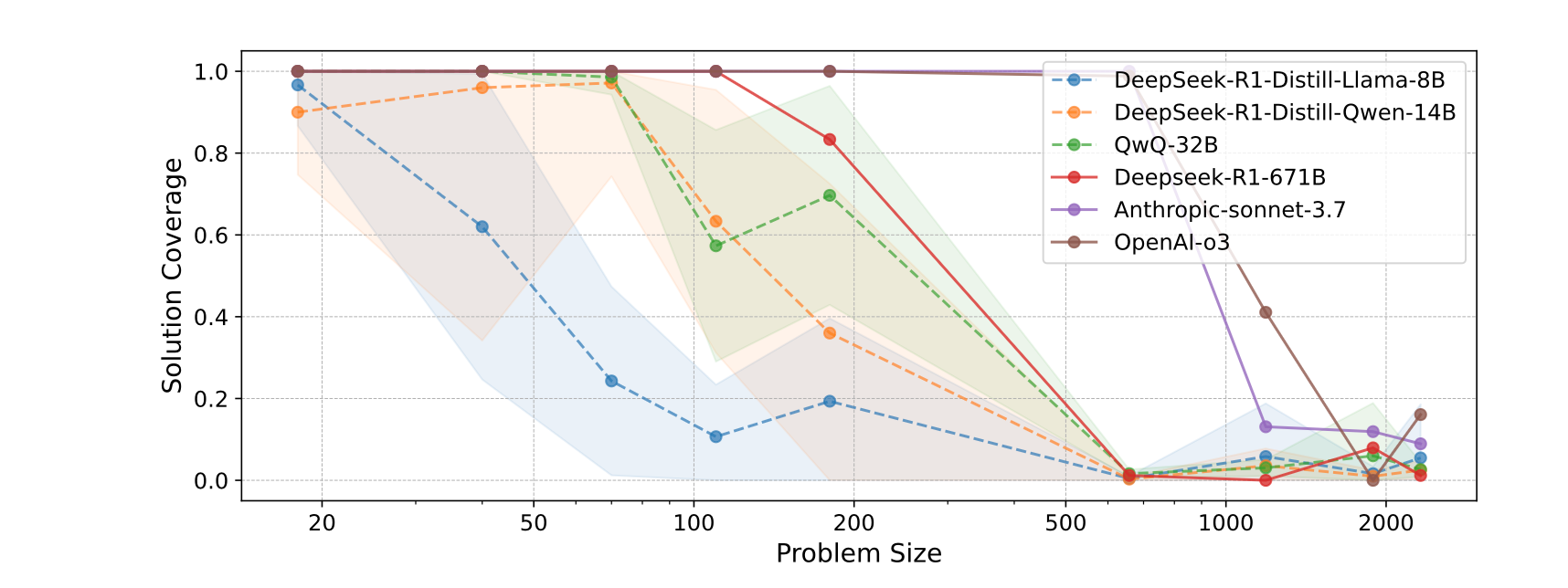
For us as AI engineers, this is useful because it reinforces a shift from evaluating only outcomes to evaluating the path the model took to get there. A model that reasons by wandering might appear competent, but it becomes unreliable in real systems that require correctness, traceability and depth. Therefore we may need new training signals, architectural biases or process based evaluation to build agentic systems we can trust. In other words, good reasoning agents need maps, not just bigger backpacks.
Worth a quick scan 👉 https://arxiv.org/abs/2505.20296v1
No spam, no sharing to third party. Only you and me.
Member discussion