
Representation Engineering with Control Vectors

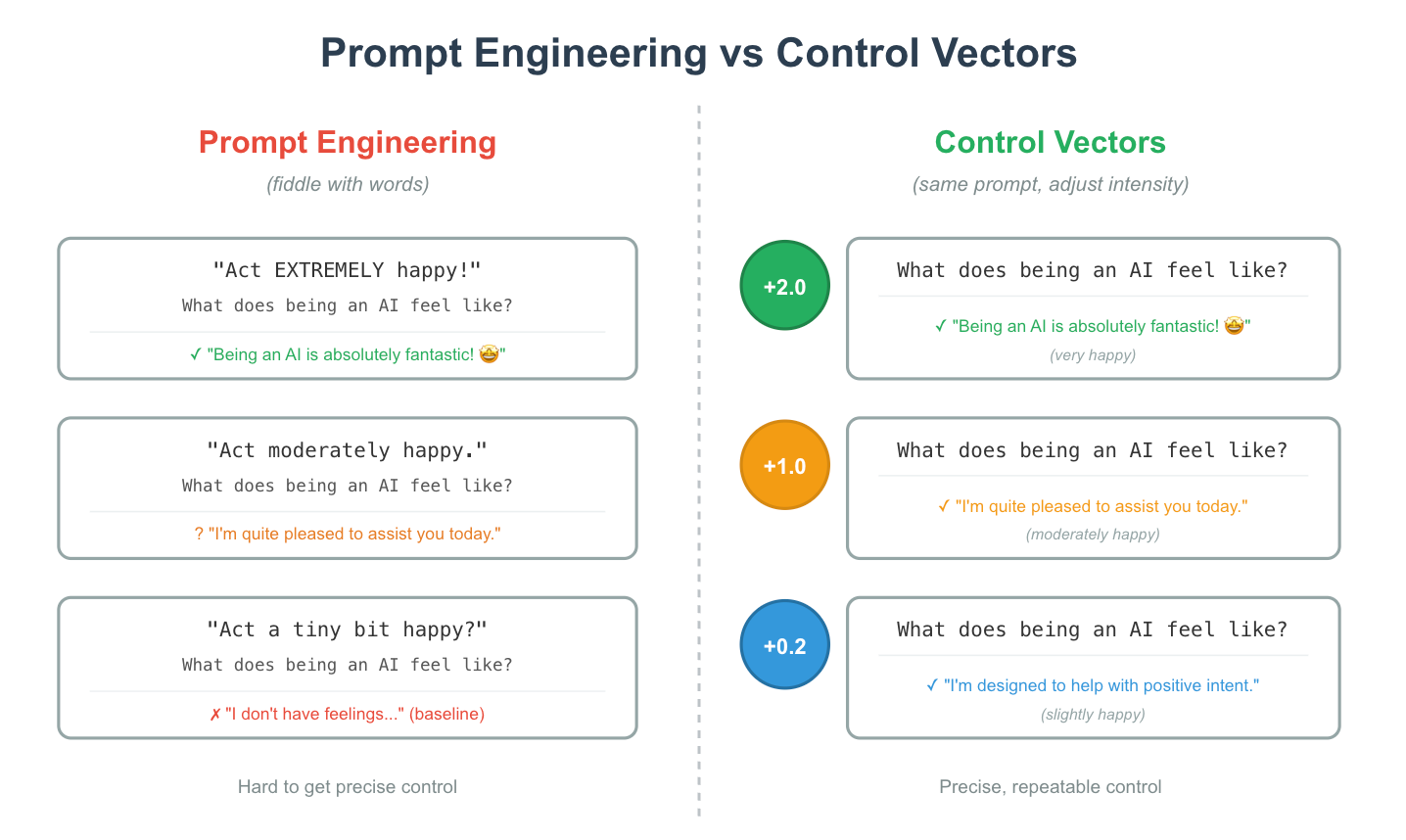
There's this technique called representation engineering that lets you modify how AI models behave in a surprisingly effective way. Instead of carefully crafting prompts or retraining the model, you create “control vectors” that directly modify the model’s internal activations. The idea is simple: feed the model contrasting examples, like “act extremely happy” versus “act extremely sad,” capture the difference in how its neurons fire, and then add or subtract that difference during inference. The author shared some wild experiments, including an “acid trip” vector that made Mistral talk about kaleidoscopes and trippy patterns, a “lazy” vector that produced minimal answers, and even political leaning vectors. Each one takes about a minute to train.
What makes this interesting is the level of control it gives you. You can dial the effect up or down with a single number, which is almost impossible to achieve through prompt engineering alone. How would you make a model “slightly more honest” versus “extremely honest” with just words? The control vector approach also makes models more resistant to jailbreaks because the effect applies to every token, not just the prompt. The author demonstrated how a simple “car dealership” vector could resist the same kind of attack that famously bypassed Chevrolet’s chatbot. It feels like a genuinely practical tool for anyone deploying AI systems who wants fine-grained behavioural control without the hassle of constant prompt tweaks or costly fine-tuning.
More details here 👉 https://vgel.me/posts/representation-engineering/
No spam, no sharing to third party. Only you and me.

Member discussion