
Rethinking RAG: Meta’s REFRAG

For the past few years, retrieval-augmented generation (RAG) has been the workhorse architecture for grounded LLM applications. You retrieve relevant chunks, convert them into tokens, feed everything into the model, and hope that your context window can stretch far enough. It’s simple and effective, but also wasteful. Each retrieved chunk is tokenised and then almost immediately turned back into embeddings inside the model. A paper from Meta's new SuperIntelligence team, REFRAG, asks a deceptively simple question: why bother converting embeddings to text, only to have the model convert them back?
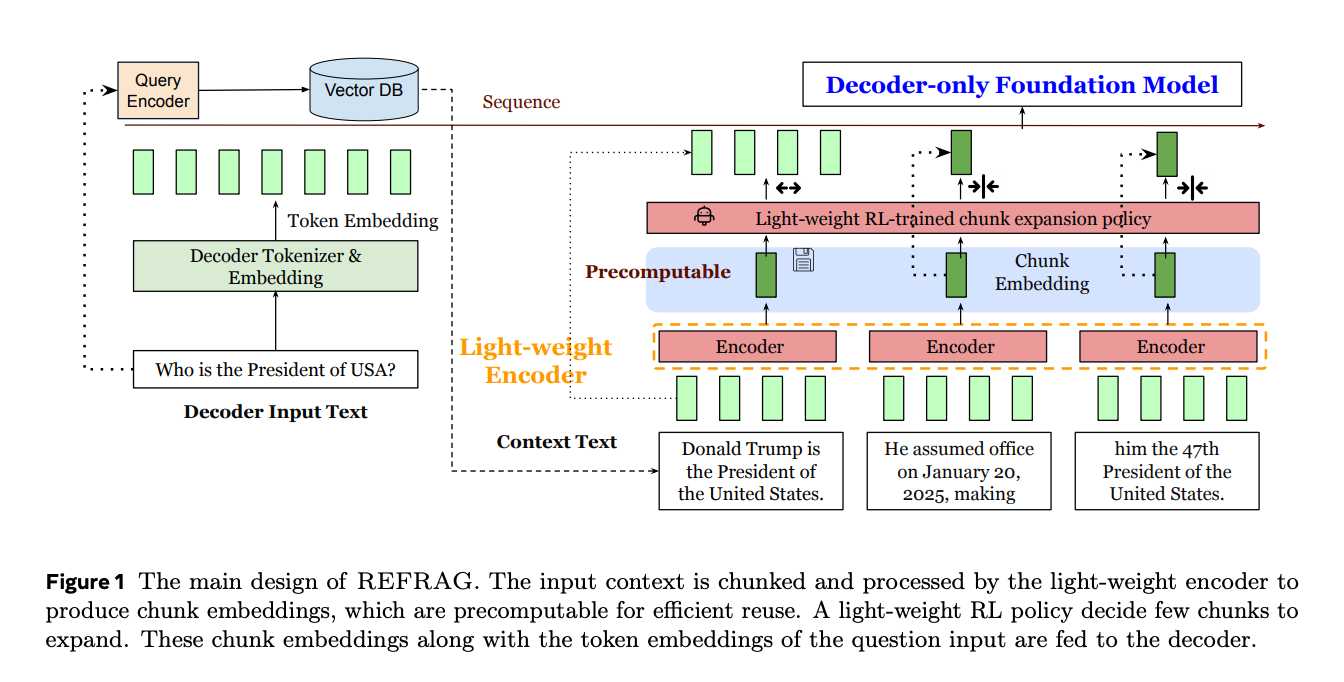
REFRAG proposes a hybrid approach. Instead of tokenising all retrieved chunks, the system keeps most of them as pre-computed chunk embeddings, feeding these directly into the LLM’s decoder. A lightweight reinforcement learning policy then decides which small subset of chunks should be expanded to token embeddings under a fixed budget. The model then receives a mixed input: a few expanded chunks at token level, and the rest in compact embedding form. This seemingly small shift has major implications for cost, latency, and context length.
The diagram below summarises the difference. On the left is the traditional RAG pipeline, where every chunk gets expanded into hundreds of tokens. On the right is REFRAG, where most chunks remain compressed and only a few are expanded selectively. The result is a much leaner decoder input, less KV-cache pressure, and significantly faster first-token latency.

KEY INSIGHT
Traditional RAG does a wasteful roundtrip: text → token embeddings (one per token) → decoder processes all. REFRAG skips the expansion step by feeding compact chunk embeddings directly to the decoder for most chunks. The policy network smartly decides which few chunks actually need to be expanded to token-level embeddings, keeping the rest in compact chunk embedding form. Compressed chunks still participate in attention but occupy far fewer positions. It's like reading cliff notes for most documents and only reading the full text for the most relevant ones. This input shortening by a factor of k (the compression rate) enables the 30× TTFT speedup while maintaining quality and extending effective context length by about 16×.
The gains are striking. Meta reports up to 30.85× faster time-to-first-token at a compression rate of 32, and throughput improvements up to 6.78×, all while maintaining no loss in perplexity or task accuracy. Because chunk embeddings are compact, effective context length can be extended by roughly 16× without retraining. This isn’t just a marginal optimisation. It’s a new way of thinking about the retrieval–generation interface, treating embeddings as first-class citizens rather than transient intermediates.
For anyone designing large-scale LLM systems, REFRAG offers a compelling blueprint. It suggests a future where retrieval is not just about finding the right information, but also about deciding how that information should be represented and consumed by the model. Instead of stuffing the context window with text, we might start streaming compressed embeddings and selectively expanding only what matters.
No spam, no sharing to third party. Only you and me.


Member discussion