
Building a Matrix-themed Chat Interface with Heroku's New Managed Inference API
The Heroku Managed Inference and Agent add-on is currently in pilot. Apply to join the Managed Inference and Agents Pilot here.
Like many developers of my generation, The Matrix left an indelible mark on my imagination. I was captivated by this mind-bending film about a programmer who discovers he's living in a simulated reality. The movie painted a dark vision of an AI-driven future, but it also presented something that stuck with me: the idea that interactions with computers could feel natural, fluid, and almost conversational.
When Heroku announced their new Managed Inference and Agent Add-on, I saw an opportunity to experiment. Like many developers, I learn best by building something hands-on, even if it's just a fun side project. What better way to explore the capabilities of this new tool than by creating a Matrix-themed chat interface? Not to save humanity from machine overlords, but to understand what's possible with modern AI tools in a familiar Heroku environment.
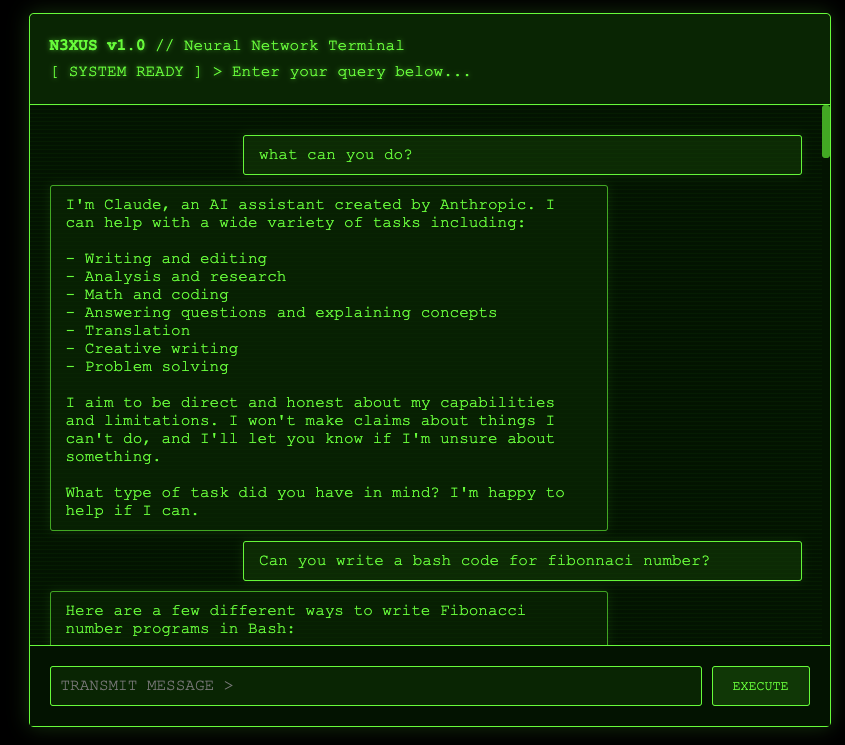
This is the story of my experimental project – a playful homage to The Matrix that helped me grasp the practical aspects of working with Heroku's new AI features. Whether you're a fan of the movie or just curious about integrating AI into your Heroku applications, I hope you'll find something useful in my learnings.
What is Heroku's Managed Inference?
Before diving into the build, let me explain what makes this new Heroku feature exciting. The Managed Inference and Agent Add-on is Heroku's solution for developers who want to integrate AI capabilities into their applications without managing complex infrastructure. It provides:
- Hosted AI models (including Claude 3.5 Sonnet) accessible through simple API calls
- Automatic scaling and infrastructure management
- Built-in monitoring and logging
- Pay-as-you-go pricing structure
Currently, the add-on is in pilot phase. You can join the waitlist by visiting Heroku's AI landing page or reaching out to your Heroku account representative.
The Project Scope
I wanted to build something that would:
- Demonstrate the capabilities of Heroku's new Managed Inference API
- Create an engaging user experience reminiscent of The Matrix's human-machine interactions
- Handle streaming responses effectively (crucial for that "real-time" feel)
- Implement proper rate limiting (because even machines need boundaries)
- Be easy to deploy and scale (true to Heroku's philosophy)
Setting Up Heroku's Managed Inference
Getting started was surprisingly straightforward. After installing the Heroku AI plugin:
> heroku plugins:install @heroku/plugin-aiI created a new app and attached the Claude 3.5 Sonnet model:
> heroku create n3xus-demo
> heroku ai:models:create -a n3xus-demo claude-3-5-sonnet --as INFERENCE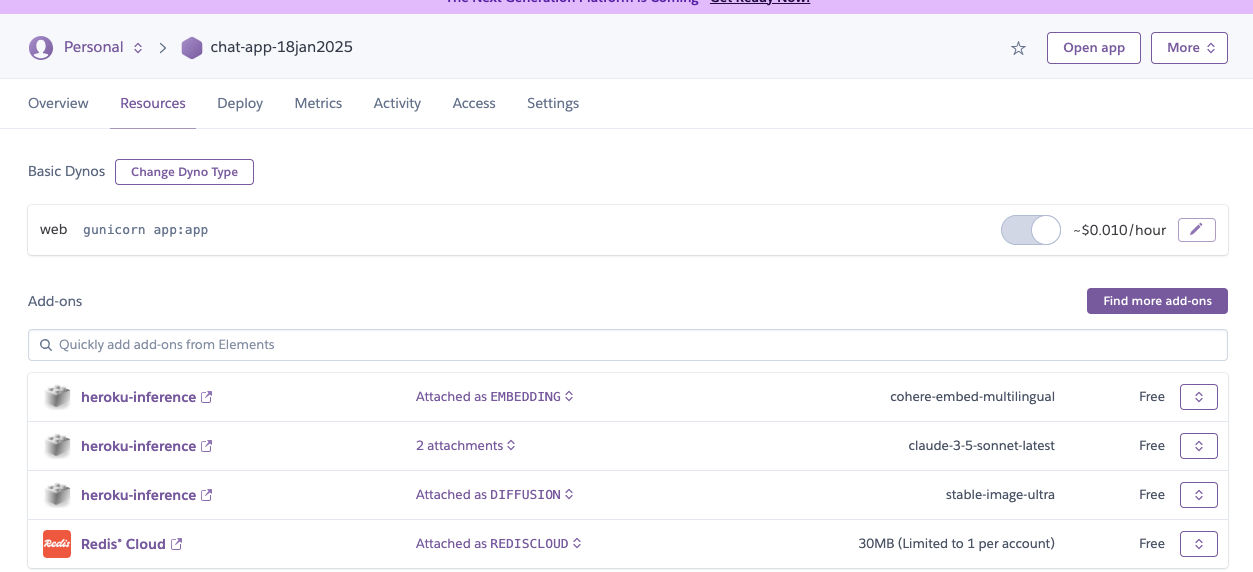
Why Claude 3.5 Sonnet? Its ability to maintain context and generate human-like responses made it perfect for creating that "machine intelligence" feel I was aiming for.
Core Implementation
The heart of the application lies in how it interacts with Heroku's inference API. Here's the basic structure:
![ENV_VARS = { "INFERENCE_URL": None, "INFERENCE_KEY": None, "INFERENCE_MODEL_ID": None } for env_var in ENV_VARS.keys(): ENV_VARS[env_var] = os.environ.get(env_var) if ENV_VARS[env_var] is None: print(f"Warning: {env_var} is not set")](https://storage.ghost.io/c/b1/a4/b1a432f8-3f63-4839-8020-97b63b6056f7/content/images/2025/08/6d14a351-c07f-4d9c-9105-2d687e4fe576_549x266.png)
I chose to structure the environment variables this way because it makes it immediately clear what configuration is missing, a lesson learned from countless debugging sessions in production.
Adding Streaming Capabilities
One of the coolest features of the API is its support for streaming responses. In The Matrix, conversations with machines felt immediate and fluid - I wanted to recreate that experience:
![def stream_chat_completion(payload): HEADERS = { "Authorization": f"Bearer {ENV_VARS['INFERENCE_KEY']}", "Content-Type": "application/json", "Accept": "text/event-stream" } payload["stream"] = True endpoint_url = ENV_VARS['INFERENCE_URL'] + "/v1/chat/completions" with requests.post(endpoint_url, headers=HEADERS, json=payload, stream=True) as response: for line in response.iter_lines(): if line: # Process and yield streaming response yield process_line(line)](https://storage.ghost.io/c/b1/a4/b1a432f8-3f63-4839-8020-97b63b6056f7/content/images/2025/08/33462c48-977a-4a9e-86b0-752417669f43_557x405.png)
The streaming implementation uses Server-Sent Events (SSE) because they provide a lightweight, unidirectional channel that's perfect for real-time text updates. Unlike WebSocket connections, SSE doesn't require maintaining a persistent connection, making it more resource-efficient for our use case.
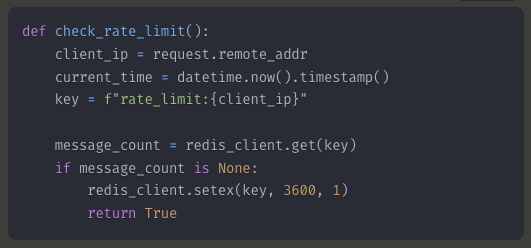
Rate Limiting with Redis Cloud
To ensure responsible API usage, I implemented rate limiting using Redis Cloud on Heroku:
The Matrix Theme: Making it Engaging
While the core functionality was important, I wanted to make the interface engaging. I chose a Matrix theme not just for aesthetics, but to create a sense of interacting with an advanced AI system:
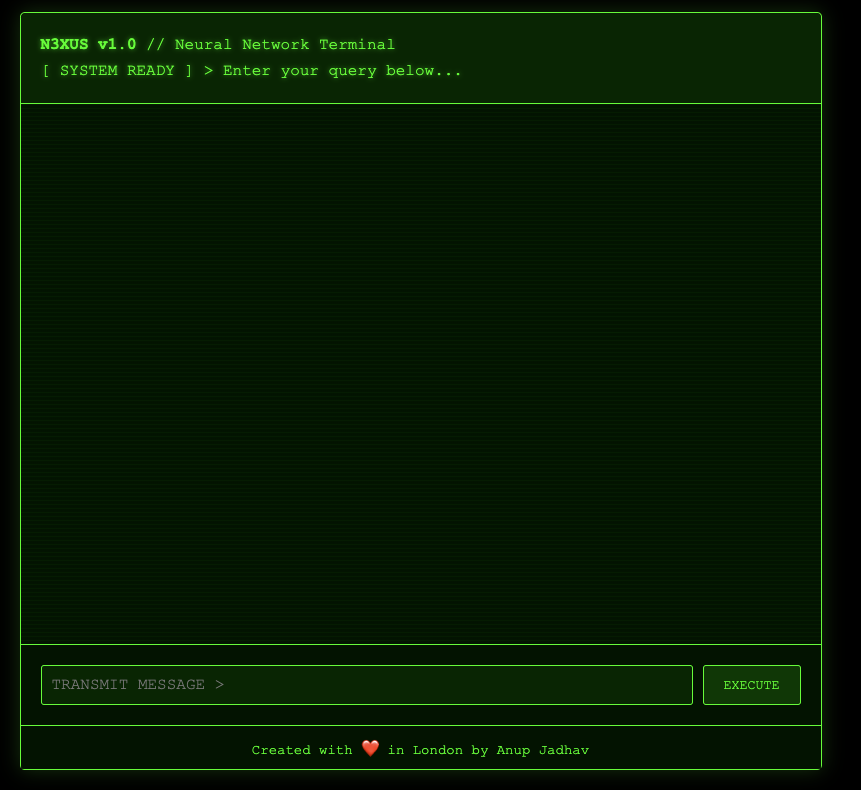
Key Learnings and Their Real-World Applications
API Design Simplicity
Heroku's Managed Inference API follows REST principles faithfully
The straightforward design means shorter development cycles
Perfect for teams wanting to add AI capabilities without extensive ML expertise
Particularly valuable for MVPs and rapid prototyping
Streaming Performance Benefits
Reduced perceived latency improves user engagement
Lower memory footprint compared to waiting for complete responses
Enables real-time error handling and recovery
Ideal for chat applications, document generation, and real-time analysis tools
Rate Limiting Strategies
Essential for managing costs in production
Prevents API abuse while maintaining service quality
Implements fair usage policies transparently
Can be adapted for different user tiers or subscription levels
Environment Management
Separation of configuration from code increases security
Makes deployment across different environments seamless
Enables easy testing and staging setups
Crucial for maintaining security best practices
Tech Stack
- Backend: Flask (Python) - Chosen for its simplicity and extensive libraries
- Frontend: Vanilla JavaScript - Keeps things light and maintainable
- Database: Redis Cloud (for rate limiting) - Perfect for real-time tracking
- Hosting: Heroku - Seamless deployment and scaling
- AI Integration: Heroku Managed Inference and Agent Add-on
- Styling: Custom CSS with Matrix theme
- Code Highlighting: Prism.js - For beautiful code presentation
Demo
What's Next?
This project is just scratching the surface of what's possible with Heroku's Managed Inference API. Some potential extensions could include:
- Multi-model support for different types of interactions
- Advanced prompt engineering for more naturalistic responses
- Custom model configurations for specific use cases
- Integration with other Heroku add-ons for enhanced functionality
Conclusion
Heroku's new Managed Inference and Agent Add-on makes AI integration remarkably accessible. By removing the complexity of model deployment and management, it lets developers focus on building great user experiences. Just as The Matrix showed us a world where machines and humans could interact seamlessly (albeit with some complications!), tools like this are making AI integration more approachable for developers of all experience levels.
Want to try it yourself? While the add-on is in pilot, you can sign up for the waitlist on Heroku's website.
No spam, no sharing to third party. Only you and me.
Member discussion