
Choosing Between RAG, Fine-Tuning, or Hybrid Approaches for LLMs
Note: Apologies for the many screenshots - unfortunately, Substack doesn't support table formatting yet.
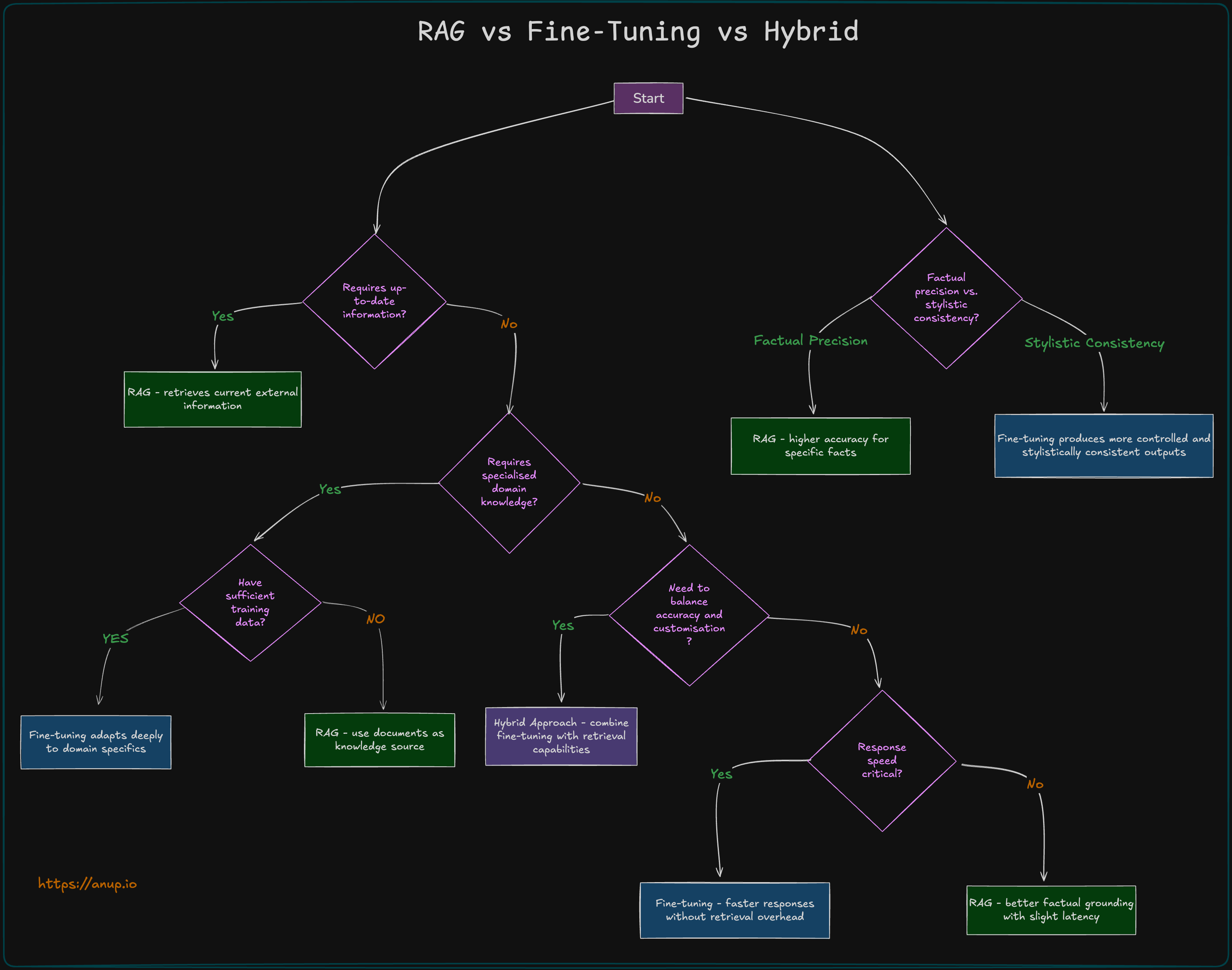
RAG (Retrieval-Augmented Generation)
RAG enhances an LLM by integrating an external knowledge base:
🔹 User Query → Retrieves relevant documents
🔹 Context Injection → Adds retrieved data to the prompt
🔹 Grounded Generation → LLM generates a response based on both query and retrieved knowledge
👉 Best for applications where knowledge updates frequently, and citation transparency is required.
Fine-tuning
Fine-tuning modifies the LLM’s internal parameters by training it on domain-specific data:
🔹 Takes a pre-trained model
🔹 Further trains on specialised data
🔹 Adjusts internal weights → Improves model performance on specific tasks
👉 Best when deep domain expertise, consistent tone, or structured responses are required.
Hybrid Approach
Combines RAG and fine-tuning:
🔹 Uses RAG for latest knowledge
🔹 Uses fine-tuning for domain adaptation & response fluency
👉 Best for applications needing both expertise and up-to-date information.
Technical Comparison Matrix
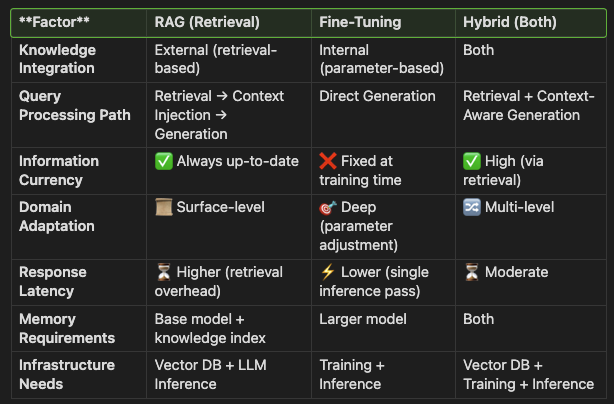
Technical Pros and Cons
RAG
✅ Pros:
✔ Factual Accuracy – Reduces hallucination risk by grounding responses in source documents
✔ Up-to-Date Knowledge – Retrieves the latest information without retraining
✔ Transparency – Provides source citations and verification
✔ Scalability – Expands knowledge without increasing model size
✔ Flexible Implementation – Works with any LLM, no model modification needed
✔ Data Privacy – Sensitive data remains in controlled external knowledge bases
❌ Cons:
⚠ Latency Overhead – Retrieval introduces additional response time (50–300ms)
⚠ Retrieval Quality Dependency – Poor search = poor results
⚠ Context Window Constraints – Limited by the LLM’s max token capacity
⚠ Semantic Understanding Gaps – May miss implicit relationships in the retrieved text
⚠ Infrastructure Complexity – Requires vector DBs, embeddings, and retrieval pipelines
⚠ Cold-Start Problem – Needs a pre-populated knowledge base for effectiveness
Fine-Tuning
✅ Pros:
✔ Fast Inference – No need for real-time retrieval, lower latency
✔ Deep Domain Expertise – Learns and internalises industry-specific knowledge
✔ Consistent Tone & Format – Ensures stylistic and structural consistency
✔ Offline Capability – Can function without external APIs or databases
✔ Parameter Efficiency – Methods like LoRA/QLoRA improve efficiency
✔ Task Optimisation – Works well for classification, NER, and structured content generation
❌ Cons:
⚠ Knowledge Staleness – Requires frequent retraining for updates
⚠ Hallucination Risk – Can generate incorrect but fluent responses
⚠ Compute-Intensive – Fine-tuning a large model requires significant GPU/TPU resources
⚠ ML Expertise Needed – More complex to implement compared to RAG
⚠ Catastrophic Forgetting – May lose general knowledge when fine-tuned too aggressively
⚠ Data Requirements – Needs a high-quality, well-labelled dataset
Hybrid
✅ Pros:
✔ Combines Strengths – Uses fine-tuning for fluency and RAG for accuracy
✔ Adaptability – Handles both general and specialised queries
✔ Fallback Mechanism – Retrieves knowledge when fine-tuned data is insufficient
✔ Confidence Calibration – Uses retrieval as a verification step for generation
✔ Progressive Implementation – Can be built incrementally
✔ Performance Optimisation – Fine-tuning improves retrieval relevance
❌ Cons:
⚠ System Complexity – Requires both retrieval and training pipelines
⚠ High Resource Demand – Highest cost for compute, storage, and maintenance
⚠ Architecture Decisions – Needs careful orchestration for optimal performance
⚠ Debugging Difficulty – Errors can originate from multiple subsystems
⚠ Inference Cost – Typically highest per-query compute cost
⚠ Orchestration Overhead – Requires sophisticated prompt engineering
Implementation Considerations
Each approach requires specific infrastructure and optimisation strategies:
- RAG → Needs a vector database (e.g., Pinecone, Weaviate), document chunking, query embedding models, and re-ranking techniques to optimise retrieval.
- Fine-Tuning → Requires high-performance GPUs/TPUs, LoRA/QLoRA for efficient adaptation, data preprocessing, hyperparameter tuning, and model versioning for long-term maintenance.
- Hybrid → Combines retrieval and fine-tuning, demanding both vector DBs and training infra, advanced prompt engineering, and custom orchestration to manage integration complexity.
Performance Metrics

Final Thoughts: Balancing Trade-offs
Choosing between RAG, fine-tuning, or hybrid depends on domain requirements, latency constraints, and compute budgets.
- RAG is the best choice when knowledge changes frequently and requires transparency.
- Fine-tuning is ideal for specialised domains with structured outputs with a consistent form or tone.
- Hybrid is most powerful when both factual grounding and domain fluency are needed.
For many real-world applications, hybrid approaches offer the best balance of knowledge accuracy and domain fluency. 🚀
Thanks for reading this post! I hope you enjoyed reading it as much as I enjoyed writing it. Subscribe for free to receive new posts.
No spam, no sharing to third party. Only you and me.
Member discussion