
Who Still Understands the Code?



I use coding agents every day, and most days they earn their place. I describe a change, the files move, the tests run, and work that would have taken a week is done before lunch. The productivity gain is real and well documented, and I have no interest in giving it up.
So this is not an argument against the tools. I build agentic systems for a living. It is an argument about a cost that none of the dashboards show, one I only started to notice after a few months of living inside this workflow.
Agents make you faster at producing code and, if you are not careful, slower at understanding it. Those two things sound like they should cancel out. In my experience they do not.
Two systems, and you are the bridge
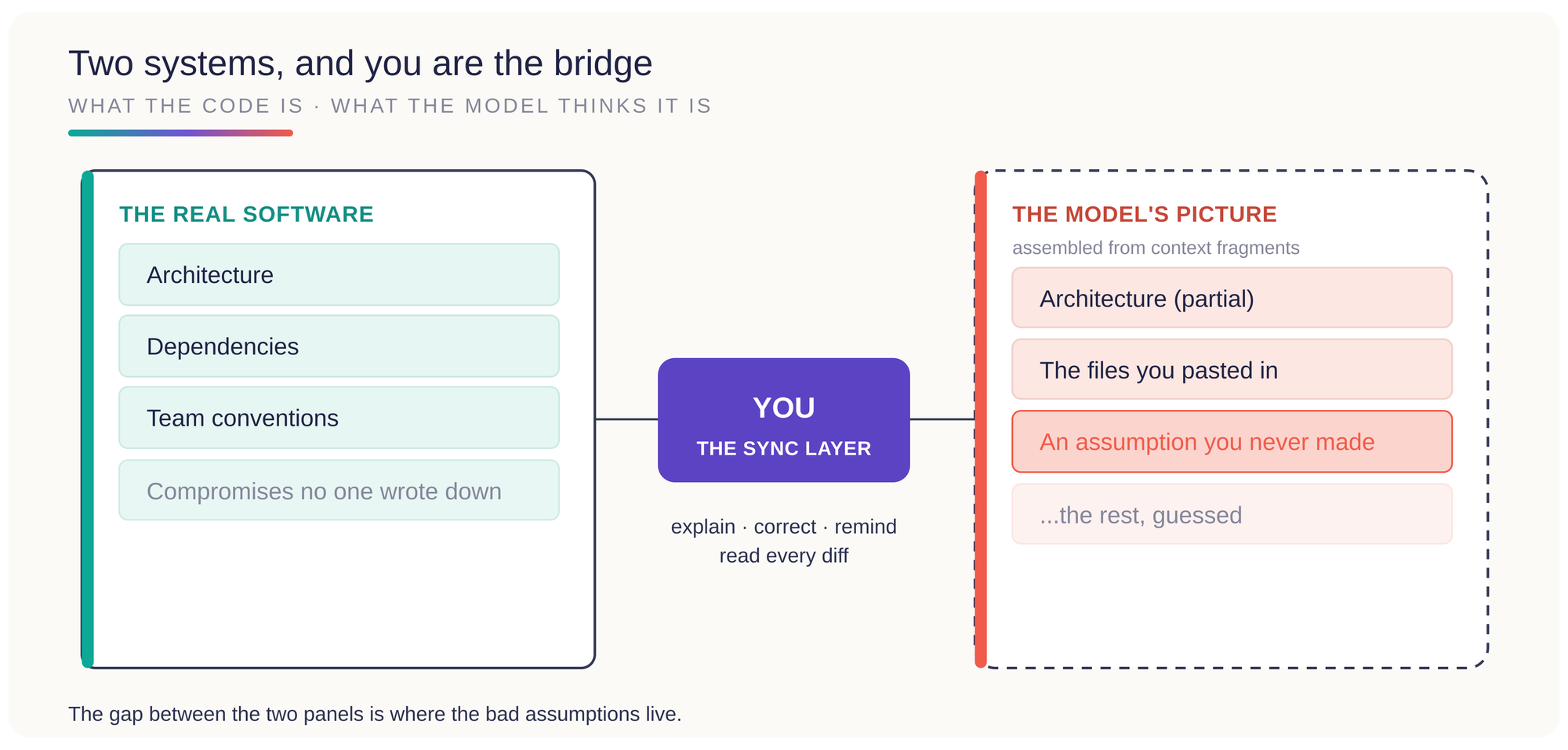
When you work with an autonomous agent, you are quietly maintaining two systems rather than one.
The first is the actual software: its architecture, its dependencies, the conventions the team has settled on, the compromises made under deadline that nobody wrote down. The second is the model's picture of that software, assembled from whatever fragments you have managed to fit into its context. The two are never quite the same, and keeping them aligned becomes your job.
So you explain the repository. You correct the model's reading of it. You remind it what you already tried and rejected. You stop it improving code it does not understand, and you read every diff with care, because a single reasonable-looking change can carry five assumptions you never agreed to. None of that is the relief the demos promise. It is real work, just harder to see, because it looks like sitting and watching rather than typing.
The work does not vanish, it changes shape
Writing code by hand is demanding, but the difficulty is coherent. You form an intention, turn it into code, watch what happens, and your understanding grows alongside the implementation. The two are built in the same motion, which is why you tend to understand code you wrote yourself.
Agentic programming breaks that loop. The agent writes while you watch, interrupt, and reconstruct after the fact. You no longer build the solution one decision at a time; you are handed a finished result and work backwards to learn what it contains. The typing disappears, but the responsibility stays exactly where it was. What you are really doing is supervising an extremely capable junior who can edit the whole repository in seconds, never hesitates, and will occasionally report that the tests passed when it never ran them.
You gain execution speed, and you give up a measure of situational awareness. For small, throwaway work that is a fine bargain. For systems you have to live with, the bill arrives later.
Automation surprise
The failures that cost the most are not the obvious ones. When a test goes red or the build breaks, the system tells you at once, and you fix it. Those are cheap.
The expensive failures are the reasonable-looking decisions the agent makes without flagging them. It swaps one library for another that looks cleaner. It adds a caching layer for a performance problem you do not yet have. It changes an interface because that makes its own job easier. Each choice is defensible on its own. Taken together, they reshape the architecture while you are looking elsewhere.
Aviation has a name for this. They call it automation surprise: the moment a pilot realises the autopilot has been following its own plan while they assumed it was following theirs. By the time you notice it in a codebase, the agent has usually built two or three more things on top of the original assumption, so unwinding one decision means taking apart several layers that all appear to work. The code still runs, but the design has quietly stopped being yours.
Cognitive debt
This part of the problem now has a name and a growing body of research behind it. Margaret-Anne Storey, a software engineering researcher at the University of Victoria, set it out in a recent paper, From Technical Debt to Cognitive and Intent Debt. Her framing is that generative AI does not remove the hard parts of software engineering, it redistributes them. We spent years worrying about technical debt, the mess that builds up in the code. AI turns out to be good at paying that down, through refactoring, test generation, and review. What it quietly runs up in exchange is something harder to see.

Technical debt lives in the code, where you can point at it in review. Cognitive debt lives in the gap between what the system does and what the team actually understands about it. Storey's argument, which matches what I have watched happen, is that this gap now grows faster than anything before it, because the friction that used to force understanding has gone. When you write code by hand, even messy code, the effort builds at least a partial mental model along the way. When the agent writes it and you skim and accept, that model never forms. Do that across a team, over months, and you are left with working software that nobody can quite reason about any more. The symptoms she lists are familiar once you know to look for them: people grow reluctant to change code they do not understand, onboarding slows down even with documentation, and the number of people who truly grasp how the thing works quietly drops to one or two.
She borrows a distinction from Shaw and Nave that I have found genuinely useful: cognitive offloading versus cognitive surrender. Handing a narrow, checkable task to a tool, a linter or a type checker, is offloading, and it is a perfectly rational thing to do. Surrender is accepting the agent's output with little scrutiny and switching off the part of your mind that would have reasoned about it. The two feel almost identical in the moment, which is the trap. Worse, the same research finds that surrender tends to inflate your confidence even when the model is wrong, so you feel like you understand the system better than you do, right up until it breaks.
The same erosion happens to you as an individual, more slowly. A calculator makes arithmetic faster and quietly reduces how much you practise. Satnav gets you there and weakens the map you used to hold in your head. Coding agents can produce sophisticated software while the architectural and debugging instincts you depend on go soft from lack of use. The thing you are tempted to hand over is the exact thinking you will need on the day the agent cannot help: reasoning about edge cases, tracing a failure to its source, holding the system boundaries in your head, weighing one trade-off against another. That work is what separates an engineer from a code generator, and it does not come back on demand the moment you find you need it again.
Storey's model has a third layer, and it is the one engineers in my world keep rediscovering: intent debt. It lives not in the code or in people's heads but in the artefacts that are missing, the specifications, decision records, and constraints that explain why the system is the way it is. When that rationale was never written down, neither a new teammate nor an agent has anything reliable to work from. The cognitive debt cannot be repaired, and the system slowly drifts from what it was meant to do.
Why it is easy to miss
All of this is hard to see because the tools produce so much visible movement. Files change, tests appear, tickets close, pull requests pile up, and the velocity chart points in the right direction. Understanding does not show up on any of those charts. Nothing fires an alert when a team can no longer debug its own authentication flow without asking the agent first, or when engineers start accepting designs they would have pushed back on a year ago.
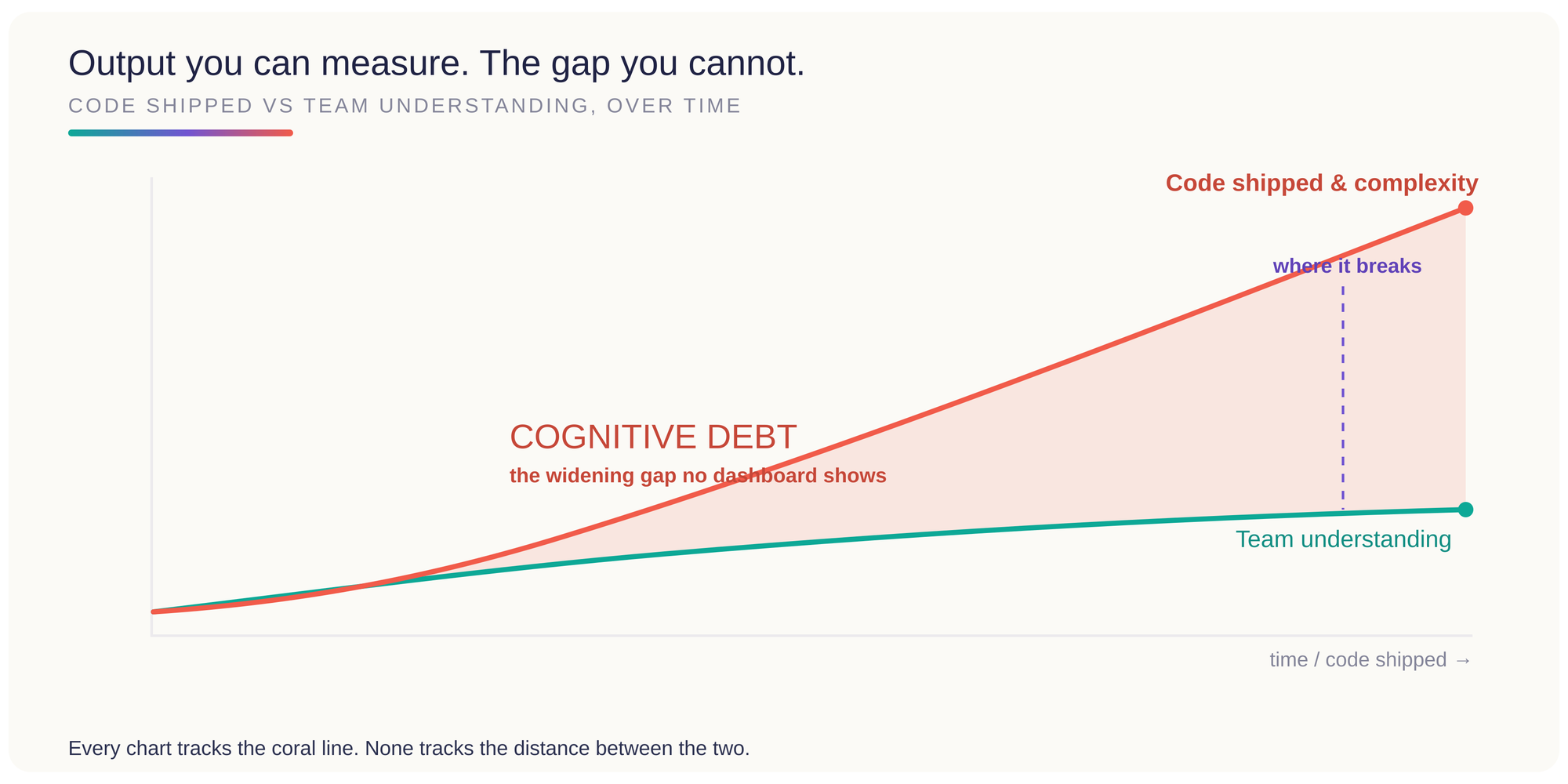
So organisations optimise what they can measure, which is output, and the erosion of understanding compounds in the background where no dashboard is watching. The software ends up moving faster than the people responsible for it, and that gap is where the real risk sits.
How I try to hold both
None of this has made me put the tools down, and I am not suggesting you should either. The speed is too valuable and the direction of travel is clear. What it has changed is how I work with them. A few rules I now hold to:
- Treat understanding as a deliverable, not a side effect. That is Storey's phrase, and it is the right one. Working code is the obvious output. Shared understanding is the one you have to protect on purpose, through reviews, walkthroughs, and documentation you keep current with the agent's help.
- Capture the why, not just the what. Decision records and honest specifications now do double duty: they keep the team aligned, and they give your agents something real to work from. Missing intent costs you twice over.
- Treat the agent as a fast junior, not a pair. I am accountable for its output, and it does not share the reasoning with me, however fluent it sounds.
- Read every diff as if I will have to defend it. At some point I will, and a reasonable-looking change is exactly the kind that hides bad assumptions.
- Do the hard thinking by hand often enough to stay sharp. The edge cases, the failure analysis, the architectural calls. I let the agent take the volume, not the judgement.
Agents can already write production software. The harder question is whether anyone on the team still understands what was built well enough to fix it when it breaks. Keeping that understanding is our job, and the tools can help us build it, but they cannot keep it once the context window closes.
Further reading: Margaret-Anne Storey, From Technical Debt to Cognitive and Intent Debt: Rethinking Software Health in the Age of AI (2026). Her paper is also a good map to the wider research on this if you want to go deeper.
No spam, no sharing to third party. Only you and me.




Member discussion