
Designing teams for an agentic world

For thirty years, software organisations were built around the same logic: hire specialists, group them into functions, put managers above them, and build a pyramid on a wide junior base. That made sense when the ability to build software was scarce. Coding agents are changing what’s scarce, so the way we’ve built things around that scarcity no longer makes sense.
What stands out to me is that most leaders are not moving slowly on AI. They are quick to adopt the tools, but much slower to change how the organisation itself works. Bolting an engine onto a horse-drawn carriage does not make it a car. After spending the past two years working through this shift, I have come to frame it through four connected questions.
Economics: buy before you build
The first question I would ask is: what is genuinely worth building yourself? The seductive story is that you train a model, or fine-tune someone else’s, on your own data and create a moat nobody else can cross. I understand the instinct because I held a version of it myself. But the economics keep pushing the other way.
- Training a frontier model gets more expensive with each step up in capability. Each step demands more compute, more data, and more capital. The bill now runs into billions, beyond what all but a handful of firms can approve.
- At the same time, running inference on an existing model keeps getting cheaper as providers compete and hardware becomes more efficient.
- So you end up pouring capital into the option that keeps getting more expensive while the cheaper alternative keeps improving. By the time your bespoke model ships, the frontier may already have moved on.
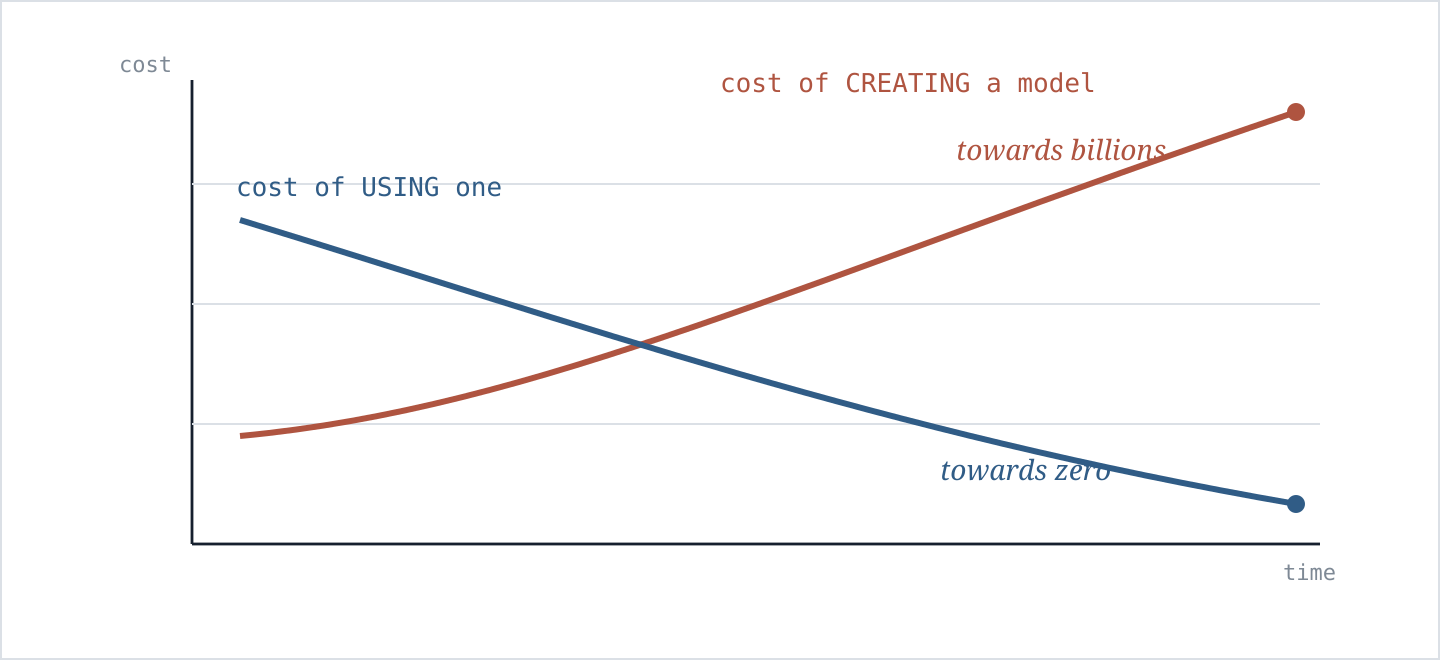
So the question is not whether you can build your own model. It is where owning one creates enough advantage to justify the cost.
That leads to a practical rule of thumb:
- Commodity capability → buy or consume. Building your own is an expensive way to recreate what you could rent.
- Differentiating and high-volume capability → consider building. But only once you understand the workflow well enough to know what you are actually building.
This decides the team directly: a consuming team needs orchestration and integration, whereas a building team needs research and infrastructure.
Talent: generalists with agents
I think the most valuable engineer over the next five years will not be the one who writes code fastest, but the one who orchestrates most effectively: someone who can point an agent at a problem, judge what comes back, steer the next attempt, and know when to stop and do the work by hand. Few senior engineers have been trained to work this way, so organisations need to hire for it and develop it deliberately.
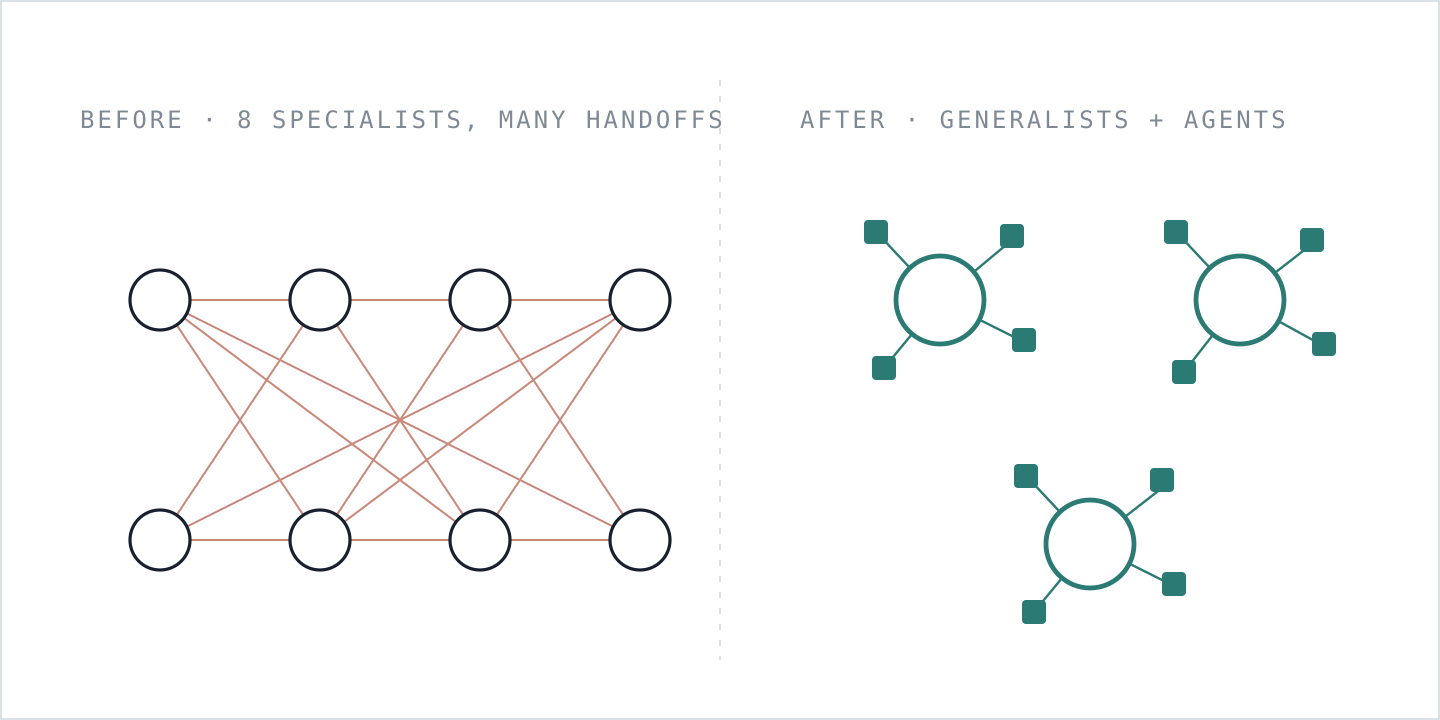
That changes the shape of the specialist team:
- The old default: eight people, each owning a narrow lane, with a handoff at every boundary.
- The emerging shape: a small group of expert generalists, each working with a fleet of agents.
- A generalist owns an end-to-end workflow rather than a narrow lane. Agents provide much of the specialist depth, while reducing the handoffs and coordination that consume so much of the week.
This does not mean every team of eight should disband next quarter. But if every new initiative still resolves into last year’s org chart, you are quietly rebuilding last year’s company.
Structure: four forces, three shapes
Of the four, structure is the hardest in my experience, because the forces pull in different directions and no design satisfies all of them at once:
- Expert multiplier: A small senior team working with agents can now produce far more, which argues for keeping teams small and senior.
- Junior squeeze: Agents absorb much of the execution work through which juniors used to learn, which tempts organisations to stop hiring them.
- Manager creep: As AI use grows, organisations feel a steady pull to add middle managers to oversee it.
- Expertise pipeline: At the same time, you still need a path through which the next generation of experts can learn.
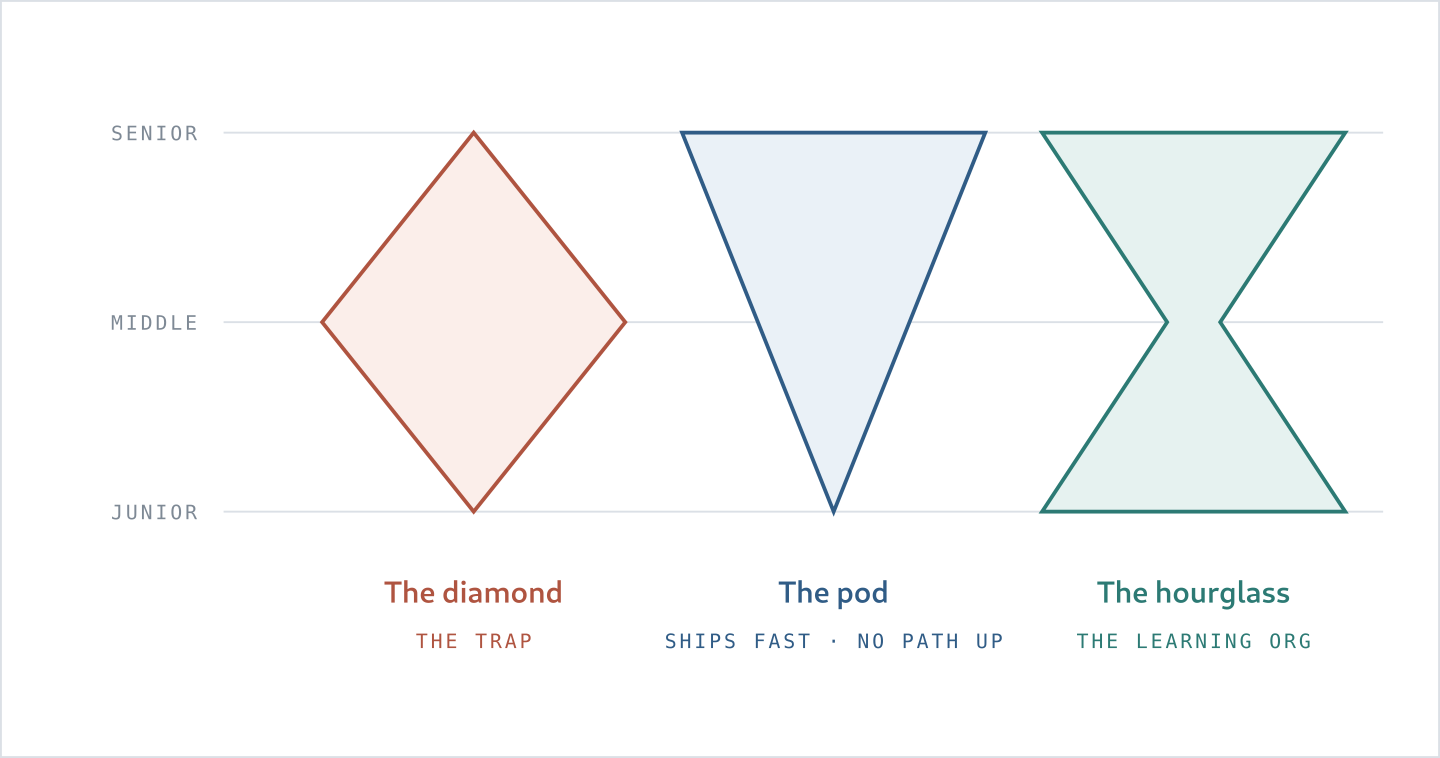
When I hold those forces together, I see three shapes:
- The diamond, which is the trap: thin at the top and bottom, swollen with managers in the middle. It looks efficient on a spreadsheet but starves the future.
- The pod: three to five senior engineers working with agents. It is excellent at shipping, but offers no path up.
- The hourglass: strong senior and junior cohorts, with a lean middle.
It took me a while to see that these shapes operate at different levels. The pod is the right shape for a delivery team; the hourglass is the right shape for the organisation that contains the pods. Left alone, most companies drift towards the diamond. Short-term incentives reward cutting the base and padding the middle; the cost arrives later.
Agents can take on much of the execution, but judgement is what remains. That judgement exists because someone spent years doing the work by hand and learning from what went wrong. If you stop training juniors, you do not merely create a hiring problem. You create an expertise problem, and expertise takes a generation to rebuild.
Structure at scale: when to build the platform
As those pods multiply, I see the leader’s job moving from owning the stack to conducting it. Security becomes code enforced at the gateway rather than a review step. Architecture becomes policy that agents follow at runtime. The platform defines the boundaries within which autonomous systems are allowed to act.
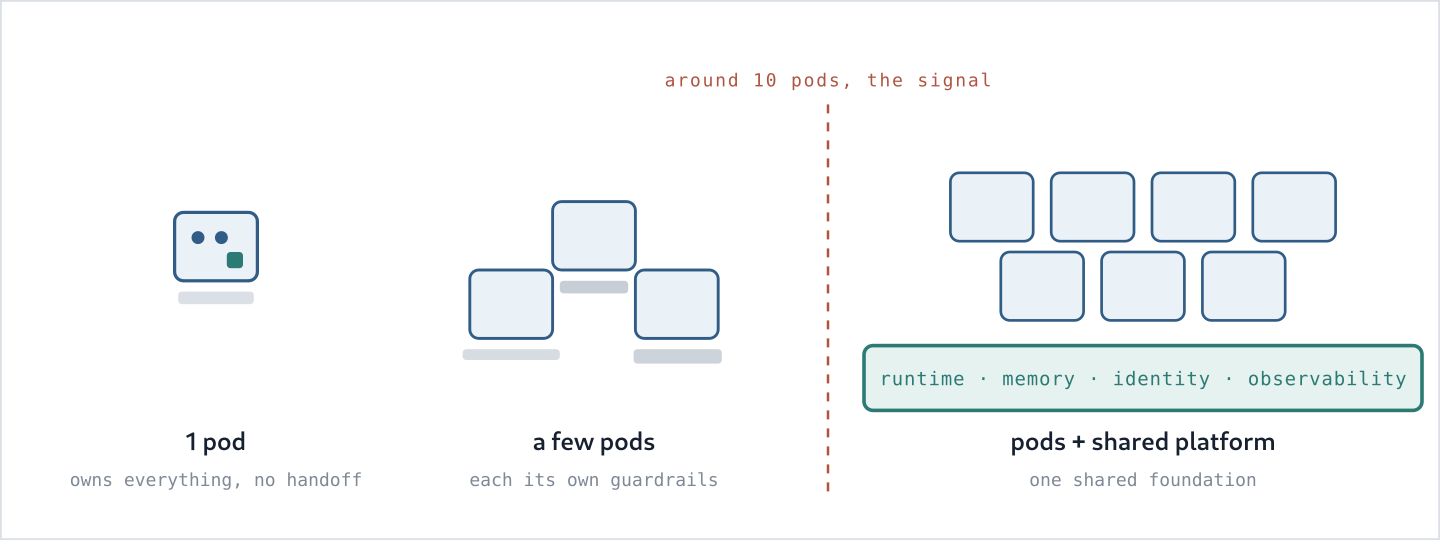
I think of this as three operating models, each suited to a different scale:
- One pod: it owns the work end to end. The people writing the agents’ instructions are also the people debugging those agents at 3am, so there is little separation and no handoff. That is why this model can deliver so quickly.
- Two or three pods: each can still invent its own guardrails. It is untidy, but manageable.
- Around ten pods: in my experience, this is where the operating model starts to break. Each pod has rebuilt authentication, observability, and identity in a slightly different way. The resulting cost, from security and compliance gaps to AI spend nobody can trace, begins to exceed the cost of a shared platform.
That is the signal to put a shared platform underneath the pods: runtime, memory, identity, and observability. The goal is to stop every team rebuilding the same foundation. The hard part is timing it well: neither building too early nor waiting too long.
Governance: probabilistic systems
The hardest shift, in my view, is cultural. Much of our discipline for running production systems, from runbooks and change boards to SLAs measured in nines, assumes that a given input will produce a predictable output. Agents are probabilistic by design. They need continuous oversight, not one-off certification. Organisations that ignore that difference will eventually pay for it.
I would start with four things:
- Give every agent a provable identity before it is allowed to act.
- Test by risk category, so oversight becomes something you operate every day, not something you merely aspire to.
- Plan for many agents acting at once. Decide what happens when they disagree, escalate, or produce behaviour that no one explicitly designed. That situation is coming whether you plan for it or not.
- Confront deskilling head-on. It is not enough to say you use agents; you have to show that you use them in a way that continues to develop the people who will eventually take responsibility.
National AI governance frameworks are already moving in this direction. Even voluntary ones are becoming part of the price of entry in regulated sectors. I would read them now as a preview of the bar everyone will eventually have to clear.
The throughline
I have framed these as four questions, not four boxes to tick, because they are not separate. They form a single chain of consequences:
- Economics decides what you build, which determines the team you need.
- Talent shifts those teams towards smaller, more senior groups centred on orchestration.
- Structure organises them as pods inside an hourglass, with a shared platform underneath once scale warrants it, so today’s efficiency does not consume tomorrow’s expertise.
- Governance treats the whole system as probabilistic, with real identity, continuous testing, and a funded path for preserving human skill.
The uncomfortable conclusion I have reached is that the structure that got you here is the wrong one for what comes next. The functions still exist, but the lines between them become less rigid.
The leaders who come out of this decade ahead will not be those who simply bolt agents onto the structure they already have. They will be the ones willing to redraw it: keeping the junior pipeline alive deliberately, making orchestration a first-class skill, building the platform when scale warrants it, and governing for probability rather than pretending uncertainty can be engineered away.
No spam, no sharing to third party. Only you and me.









Member discussion