
Note: See DeepSeek addendum near the end
Large Language Models (LLMs) can seem intimidating because of their enormous numbers. You've probably heard people throw around terms like "7B model" or "175B parameters" when talking about AI. It might feel like you need a maths degree to understand what’s going on under the hood. Let's break this down in a way that makes sense.
Model Size (Parameters)
Model size usually refers to the number of parameters1 in an LLM. Think of parameters as the “knobs and switches” that get fine-tuned during training. A bigger model, measured in billions or even trillions of parameters, can learn more patterns from data. That often translates to better performance. For instance:
Gemma 2B has 2 billion parameters.
Mistral 7B has 7 billion parameters.
GPT-4 is rumoured to have around 1.76 trillion parameters.
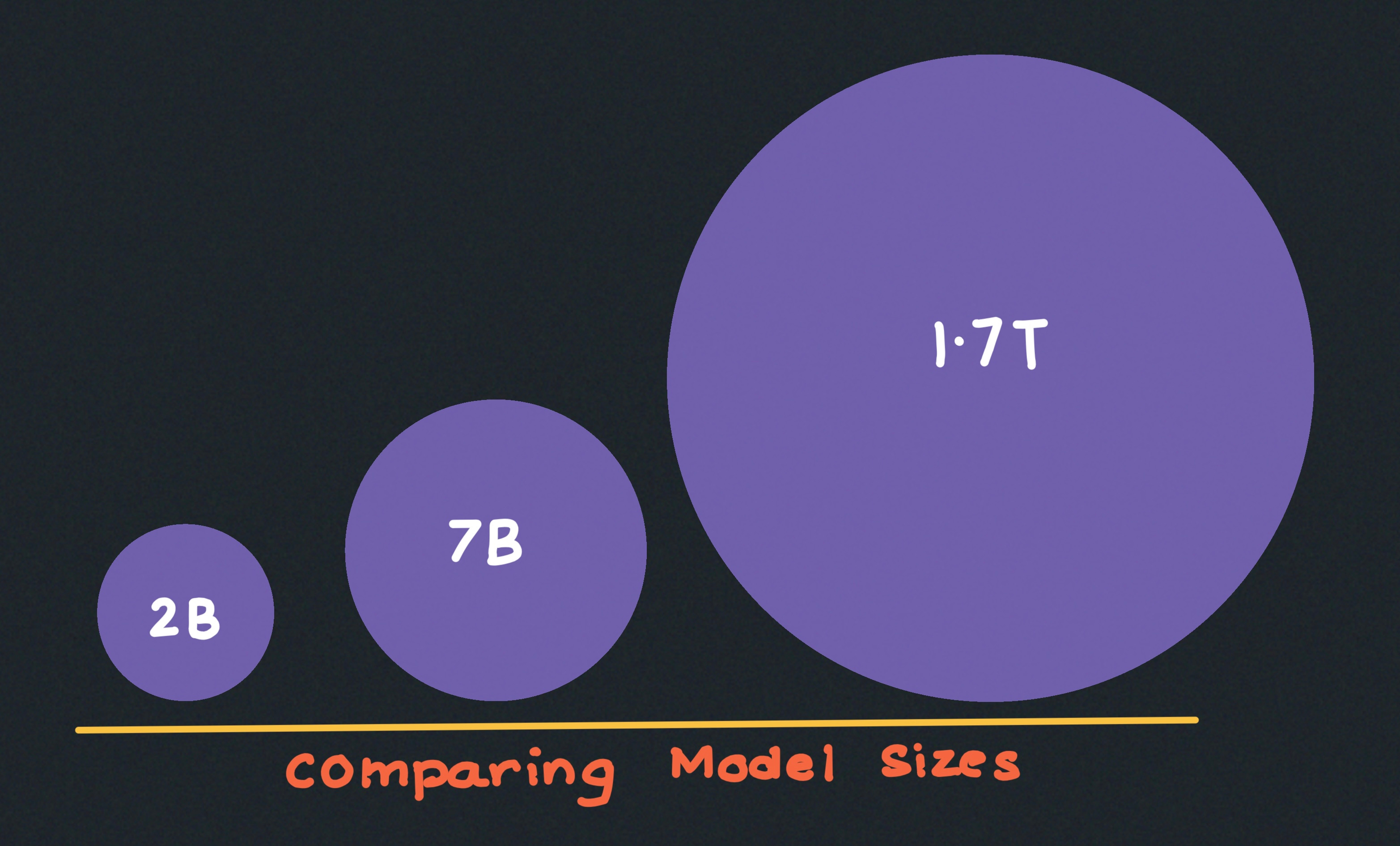
A larger number of parameters doesn’t always guarantee better performance. It also depends on how much data the model is trained on and how well the training process is done.
A 13B-parameter model trained on only one sentence ("I like GPUs.") will perform terribly compared to a “smaller” 7B-parameter model trained on internet scale data.
Sparse Models and Mixture of Experts
Most models are “dense,” meaning they treat all parameters as active. Sparse models, on the other hand, have a lot of parameters that stay at zero most of the time.
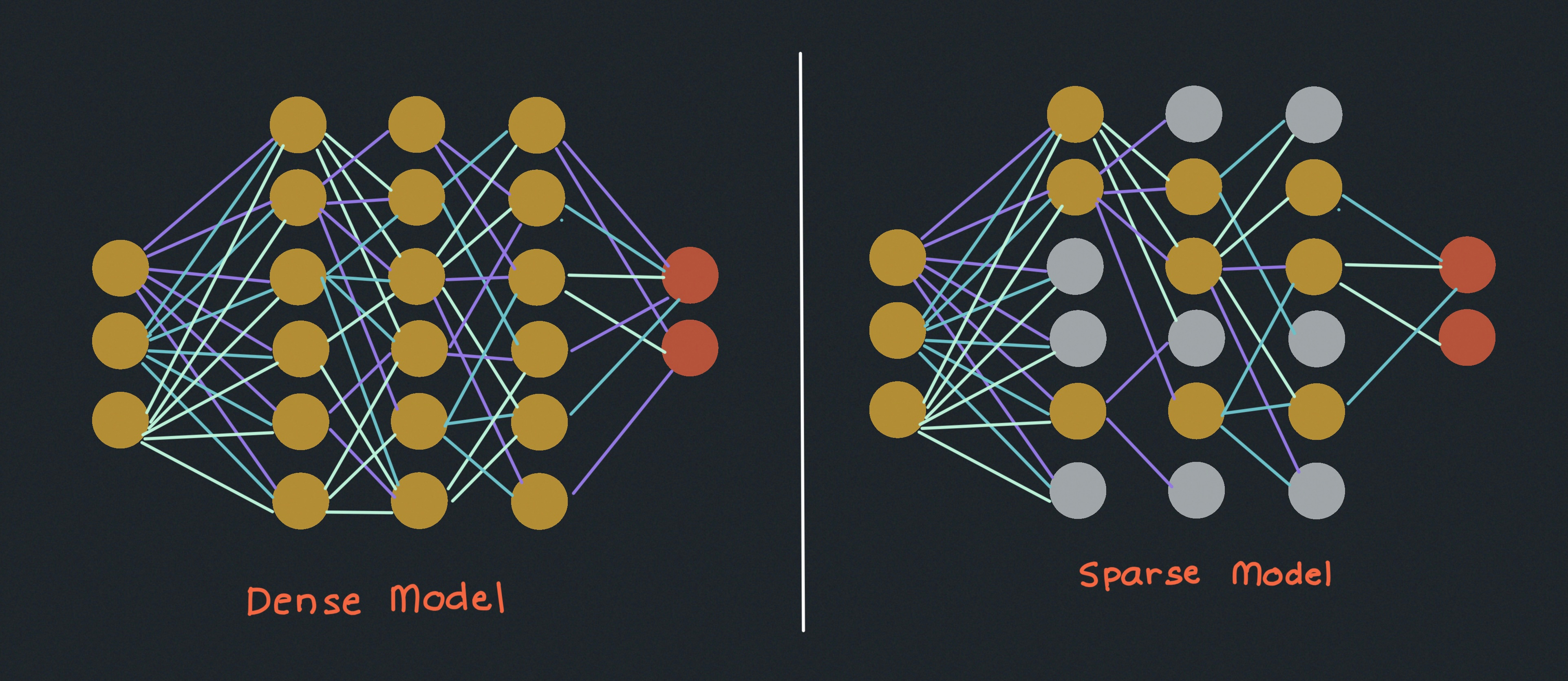
One popular approach is known as “mixture of experts.” Take a model like Mixtral 8×7B, which is split into eight “experts,” each with 7 billion parameters. If no parameters were shared among these experts, the total would be 8 x 7B = 56B. However, due to some shared parameters, the model has only 46.7 billion.
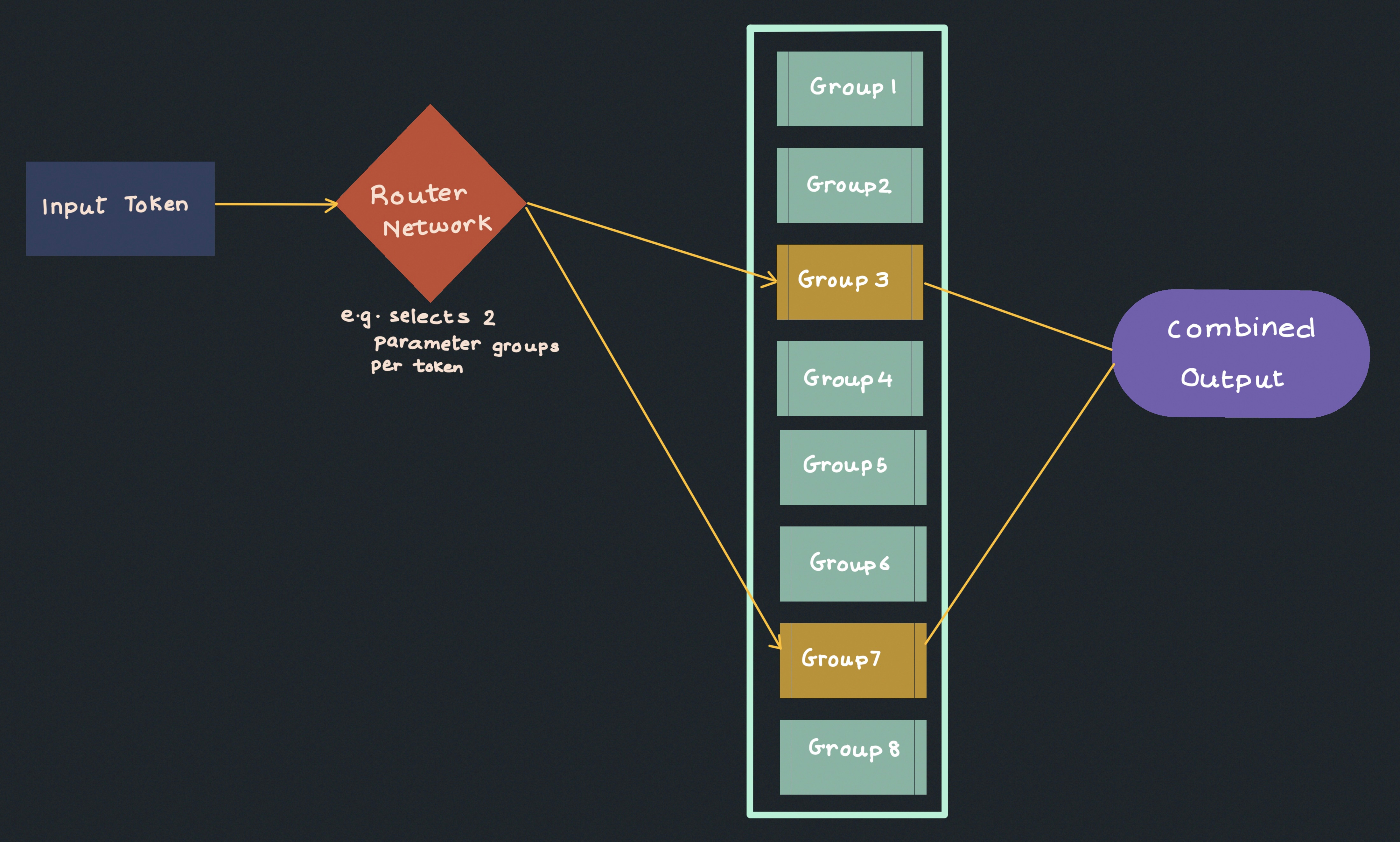
At any given time, only a few experts are active for each token, so even though the model’s total parameter count is high, it doesn’t use all parameters at once. This helps save compute resources in practice.
Training Data: Quantity, Quality, and Diversity
Parameters matter, but they aren’t the whole picture. It’s also about data:
Quantity: The number of tokens (pieces of text) that a model is trained on. Some models use trillions of tokens. For example, LAMA1 used 1.4 trillion tokens, LAMA2 used 2 trillion, and LAMA3 used 15 trillion.
Quality: Well-curated text matters. A random pile of meaningless text won’t help much.
Diversity: Training data from many sources helps the model handle different topics.
Data quantity is usually measured in tokens rather than training samples like sentences or documents. That’s because different tokenization processes might split the same text into different numbers of tokens. If a model uses two “epochs” on a 1-trillion-token dataset, that amounts to 2 trillion training tokens in total.
Compute and FLOPs
Training large models requires a lot of compute. This is where FLOPs (floating point operations) come in. FLOP measures the number of floating point operations performed for a certain task. FLOPs2 the total amount of computational work needed. For example, GPT-3 (175B parameters) was trained with about 3.14×10^23 FLOPs. PaLM2 used 10^22 FLOPs. These huge numbers tell us how much raw calculation went into training.
GPUs have an advertised peak performance in FLOP/s (FLOPs per second). Actual utilisation is often lower. Getting 50% of peak performance may be acceptable, and 70% can be considered great.
Table of Example Models
Below is a simplified table comparing some of the concepts we’ve covered. All numbers are approximate and meant to give you a sense of scale:

Scaling Laws and Budgeting
Teams rarely have unlimited money or access to massive data centres. The now famous Chinchilla Scaling Law states that for compute-optimal training, you need about 20 times as many training tokens as parameters. If your model is 2 billion parameters, it should see about 40 billion tokens to get the best results for the available compute.
Scaling laws also tell us that increasing model size and data leads to better results—but the improvements come at an ever-increasing cost. The last few percentage points of accuracy might be far more expensive to achieve than earlier gains.
Beyond the Numbers: Inverse Scaling and Real-World Bottlenecks
Sometimes bigger models can do worse on certain tasks. Anthropic found that more alignment training led to more political and religious opinions in the model’s output—likely not what they wanted. Also, there’s worry about running out of high-quality public data to feed these large models. And then there is the electricity problem. Data centres already eat up a large chunk of global power. That share could explode if we keep building bigger and bigger models without finding more energy or optimizing usage.
DeepSeek: When Innovation Shines
It would be remiss of me not to include why DeepSeek is causing such a stir and why people and financial markets are losing their minds over it.
DeepSeek introduced three distinct variants: DeepSeek-R1-Zero, DeepSeek-R1, and DeepSeek-R1-Distill.

Image Attribution: Understanding Reasoning LLMs by the inimitable Sebastian Raschka.
Training LLMs is expensive, and companies like OpenAI and Anthropic spend between $70 and $150M (rumoured) on compute per model. Let that sink in - that's just for Compute. They need massive data centres packed with tens of thousands of GPUs to make this happen. Everyone assumed that better AI models needed more compute power, which meant hundreds of millions in investment. Until now.
DeepSeek flips this script by building a model that matches or even beats GPT-4 and Claude on many tasks - and they do it with just under $6M3. That's like getting a Ferrari's performance for the price of a Toyota. They pulled this off with several clever innovations:
Think of traditional AI as storing numbers like your bank balance with tons of decimal places (32 of them). DeepSeek found a way to do the same calculations accurately with just 8 decimal places. That means they need way less memory to get the same results.
They took the innovation of "expert systems" and sparse models (explained above) to another level, so instead of one big model trying to know everything, they have specialised experts that only wake up when needed. Very similar to Mixtrals LLM.
Their "multi-token" system is like reading multiple words at once instead of one at a time - imagine reading "New York City" as one chunk rather than three separate words. This makes it at least 2x faster and works correctly 90% of the time. This makes a huge difference when you're processing billions of words.
The cherry on top - it's open-source with a very generous MIT license which allows for unrestricted commercial use. This could unleash a wave of innovation from developers, researchers, and creators who were previously priced out of the AI race. Sometimes the biggest breakthroughs come not from throwing more resources at a problem, but from fundamentally rethinking how we solve it.
Wrapping Up
LLMs can be understood by looking at three main numbers:
Number of Parameters – indicates the model’s potential learning capacity.
Number of Training Tokens – indicates how much information the model has absorbed.
Number of FLOPs – indicates the compute required for training, and therefore approximates the overall training cost.
These three factors help explain why building LLMs is so resource-intensive. Researchers often balance them to reach the best performance possible for a given budget. And even if you find the “perfect” scale today, new breakthroughs in sparse modelling, mixture of experts, and improved data quality might change the rules tomorrow.
LLMs continue to grow and evolve. It’s exciting to see just how far they can go—but it’s also important to remember that bigger is not always better. The best results come from the right balance between data, compute, and careful model design.
Thanks for reading! Feel free to share your own thoughts or experiences on training large models.
A parameter is learned (or updated) by the model during training, whereas a hyperparameter is set by the user to guide how the model learns. Examples of hyperparameters include the number of layers, dimensionality, epochs, batch size, and learning rate.
Not to be confused with FLOP/s, floating point operations per Second. FLOP/s measures a machine’s peak performance.
There is some contention around the reported $6 million training cost for DeepSeek-R1; it's likely being confused with DeepSeek-V3, released last December.