
Thinking Smarter, Not Harder: How LLMs Can Learn on the Fly
...or how I learned to stop worrying and love inference-time scaling
When it comes to AI, there’s an ongoing arms race: bigger models, more data, more compute. But what if that’s not the most efficient way forward?
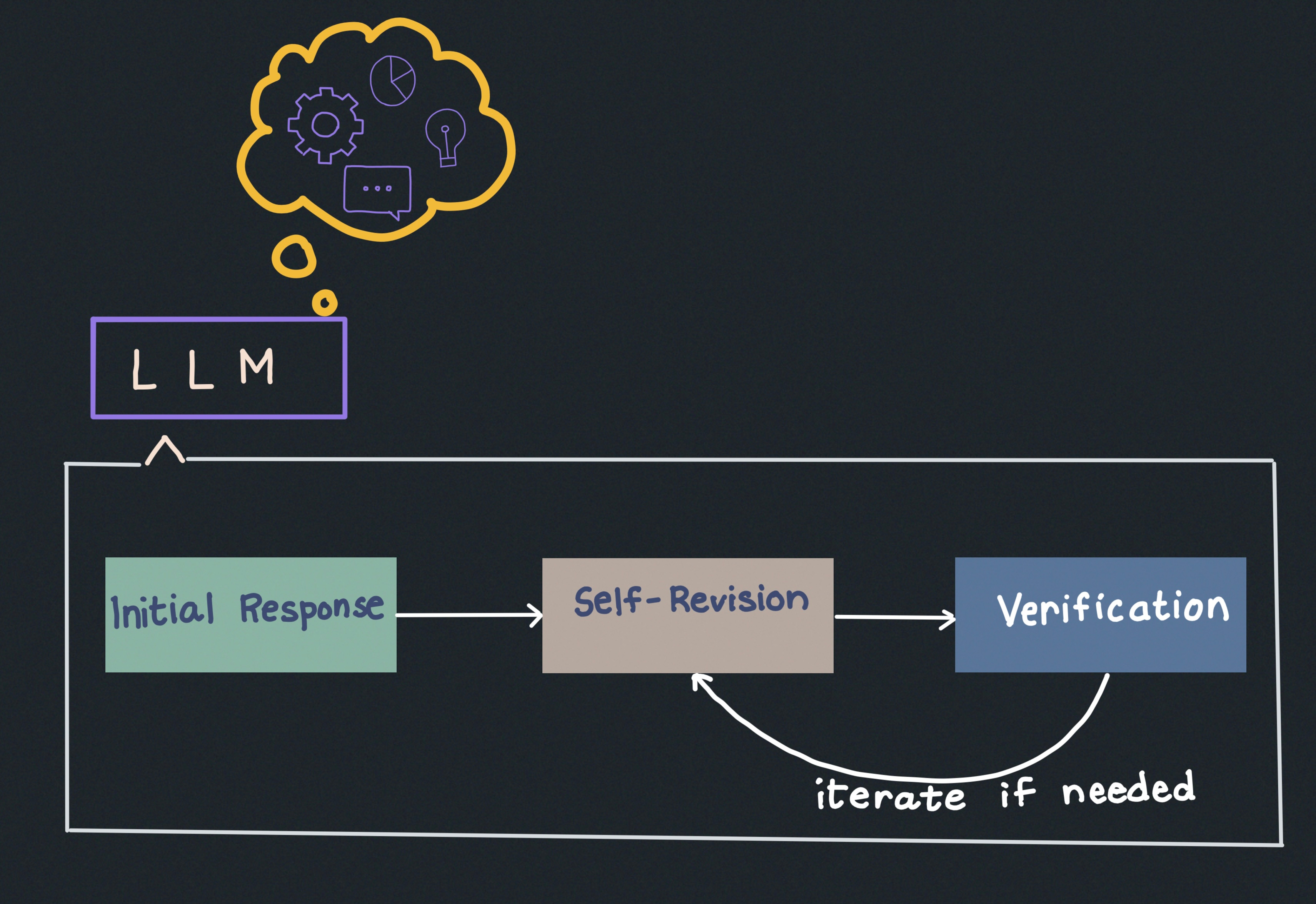
A recent study1 by Google DeepMind challenges this assumption, showing that giving LLM more time to “think” during inference can be just as effective—sometimes even more so—than training ever-larger models. Instead of just memorising more information during pre-training, AI can improve its answers by reasoning more deeply at runtime.
This shift highlights the importance of inference-time scale—the amount of compute used to generate a response during inference. Unlike pre-training, where AI models passively absorb information, inference-time compute allows LLMs to dynamically refine their responses in real time. It includes techniques like chain-of-thought prompting, iterative refinement, and using external verifiers.
Inference-Time Scaling: Smarter Thinking, Not Just More Training
Traditionally, AI models are trained upfront—like cramming for an exam. But when faced with a tough question, humans don’t just rely on what they’ve memorised; we take a moment to think critically. Well, some of them do.
Inference-time scaling brings this ability to LLMs. It allows models to re-evaluate their initial responses, explore alternative solutions, and refine their answers on the fly—all without requiring massive increases in training data.
How Does It Work?
The study explores two key approaches:
Self-Revision: The model iteratively refines its own answers, learning from mistakes and improving accuracy step by step.
Verifier-Guided Search: Instead of generating a single response, the model produces multiple candidates and evaluates them against a verifier, selecting the most promising solution.
These strategies fall under test-time scale, which refers to the compute used during inference, often exceeding what was used in pre-training. This is especially important in benchmarking AI performance on challenging test sets, where more computation at runtime can significantly improve accuracy.
The research found that the effectiveness of these methods depends on problem difficulty. For easier tasks, simple self-revisions work well, while complex problems benefit from structured search-based strategies.
Note: The terms “test-time scaling” and “inference-time scaling” are often used interchangeably and refer to methods applied during the inference phase to enhance an AI model's performance.
OpenAI o1: Pushing Inference-Time Scaling Even Further
OpenAI’s recently announced o1 model takes this idea even further by dynamically allocating compute at inference time—not just based on task complexity but also to optimise cost and efficiency. Instead of running a massive model on every prompt, o1 can intelligently decide how much compute to use per query, ensuring that simple questions are processed quickly while more complex reasoning tasks get additional compute.
This represents a paradigm shift—instead of relying on a monolithic model that always runs at full power, AI can adapt its reasoning depth dynamically. It’s an evolution of the principles discussed in the research, demonstrating that inference-time compute is not just an optimization—it’s a core architectural advancement.
Side note: Deepseek-R1 is more efficient at inference time, which suggests DeepSeek put more effort into training, while OpenAI relied more on scaling during inference for o1. Which is better? 🤷🏾 You decide
Why This Matters
This shift in thinking has big implications:
✅ Smarter, more efficient AI – Test-time compute allows smaller models to match or exceed the performance of 14× larger models by allocating compute dynamically, making AI more cost-effective and scalable.
✅ Optimised deployment for Agentic AI – AI agents can adapt compute usage based on task complexity, enabling on-device intelligence, lower energy consumption, and real-time decision-making without massive infrastructure.
✅ Self-improving, autonomous AI – AI systems can revise responses, refine reasoning, and adapt dynamically at inference, unlocking iterative learning, multi-step planning, and strategic problem-solving.
✅ More reliable AI agents – By assessing uncertainty, revising errors, and exploring alternatives, inference-time scaling makes AI more robust, resilient, and trustworthy, especially in high-stakes domains like finance, healthcare, and legal automation.
All of these benefits tie into the broader compute-time scale, which measures the total computational cost across an AI system’s lifecycle—from pre-training and post-training to real-time inference. Optimising this scale is key to making AI systems both powerful and efficient in real-world applications.
The Tradeoff: When Should We Train More vs. Think More?
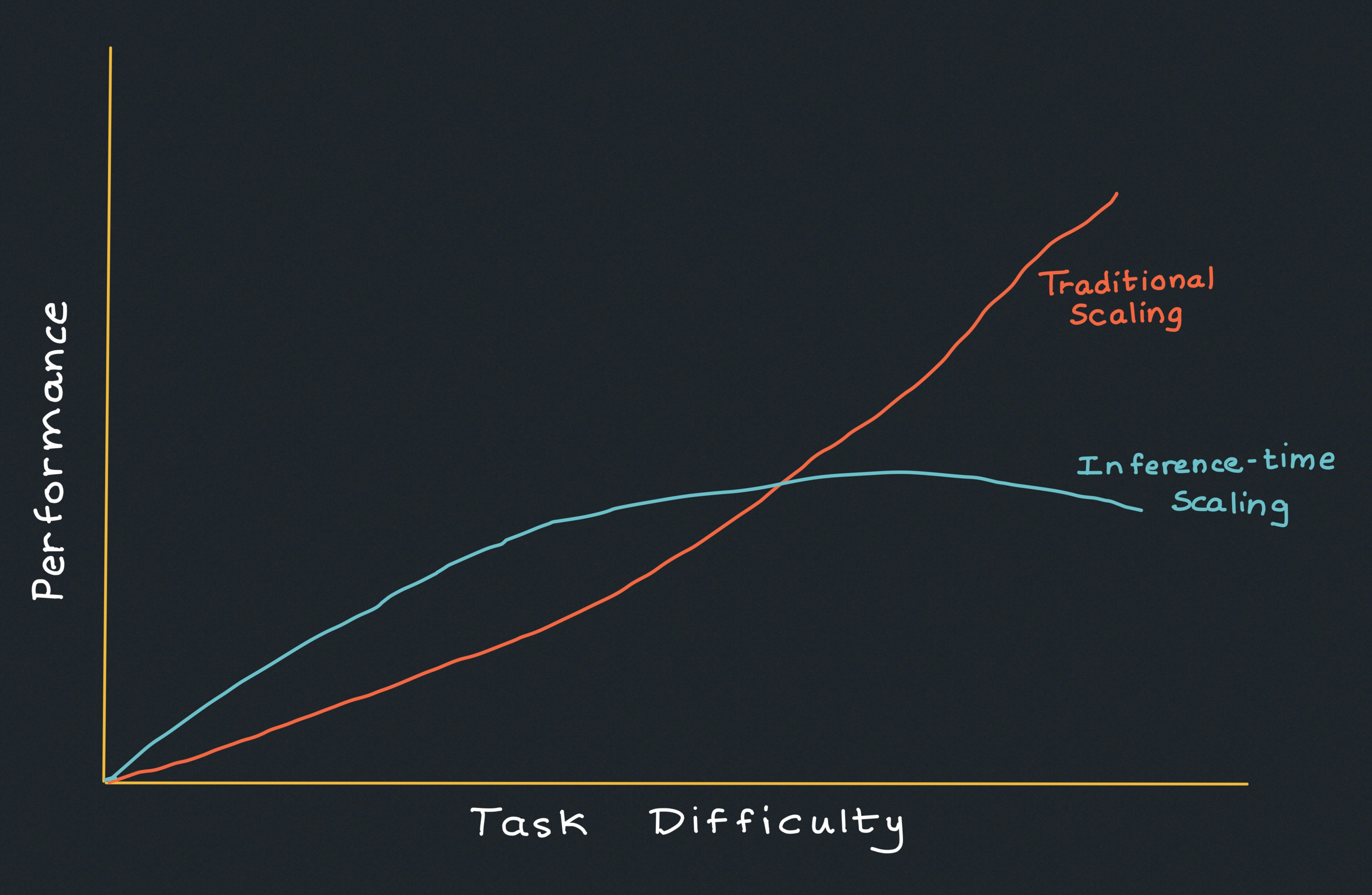
The study also examined whether test-time compute could replace additional pre-training. The answer? It depends.
For easier and medium-difficulty tasks, inference-time compute often works just as well, if not better, than scaling up model size.
For extremely hard problems, increasing pre-training compute is still the best approach—for now.
It can be expensive 💸 - while it doesn’t require extra training, inference time scaling technique raises inference costs and becomes pricier at scale as user or query volume grows.
The Future of AI: Smarter, Not Just Bigger
AI progress isn’t just about making models larger—it’s about making them more adaptive, resource-efficient, and capable of reasoning on demand.
With innovations like compute-optimal inference scaling and models like OpenAI’s o1 that dynamically adjust compute on the fly, we’re entering an era where AI doesn’t just process information—it thinks better.
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters - https://arxiv.org/pdf/2408.03314