
Query, Key, Values

[As part of my TIL series, building an intuition about Q, K, V]
A good way to understand QKV is this:
Attention is a soft lookup operation.
Given a token, the model asks:
“What information should I pull from the other tokens?”
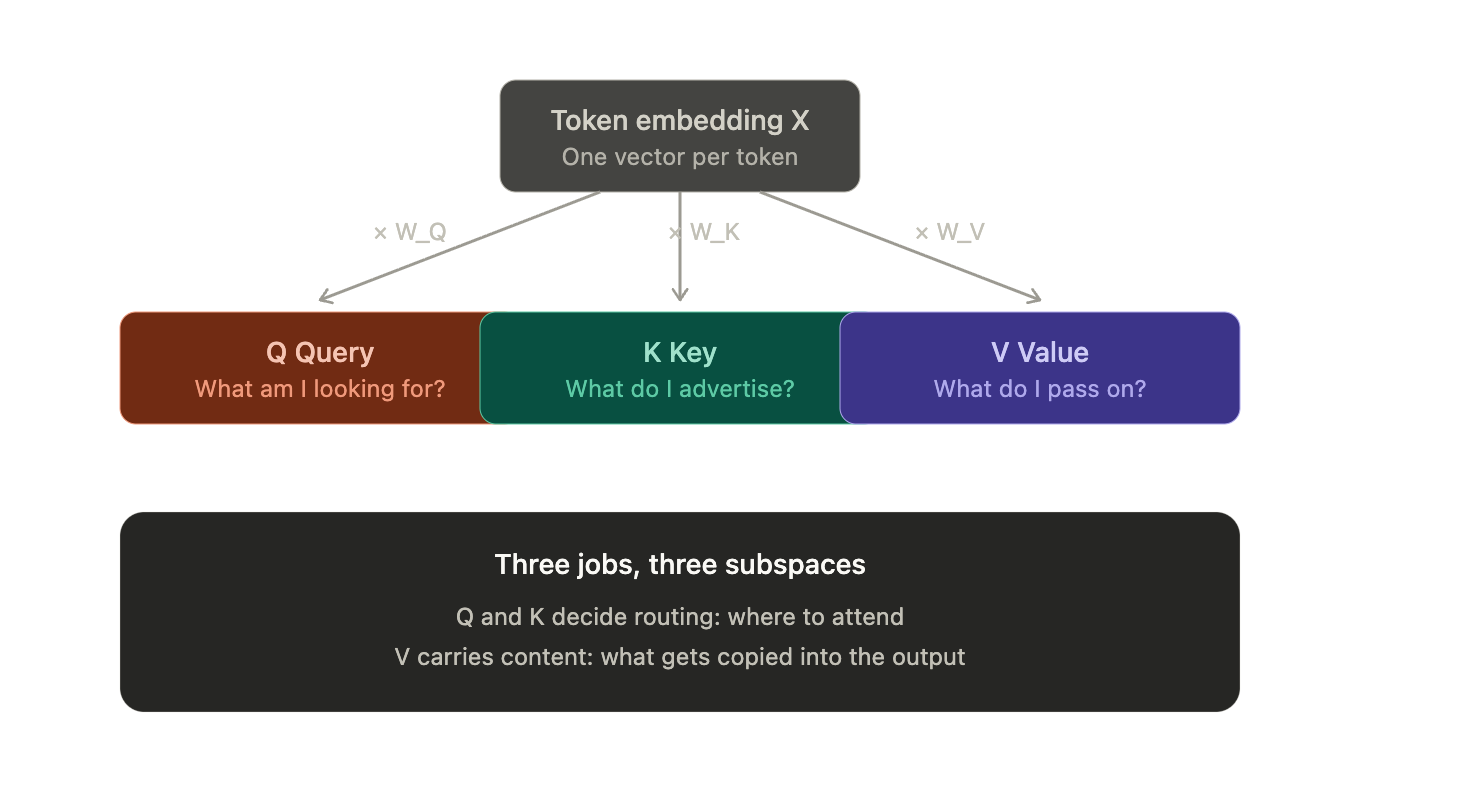
Q, K and V are just three different projections of the same input token embeddings.
The simplest mental model
For each token, the model creates three vectors:
- Query -> "What am I looking for?"
- Key -> "What do I contain/advertise?"
- Value -> "What information should I pass on if selected?"
So attention works like this:
- Compare a token’s Query against every other token’s Key.
- Turn those similarities into weights.
- Use those weights to take a weighted average of the Values.
The formula is:
Attention(Q, K, V) = softmax(QKᵀ / √dₖ) VMeaning:
similarity scores = QKᵀ
attention weights = softmax(similarity scores)
output = attention weights × VConcrete example
Take the sentence:
The dog chased the ball because it was excited.When processing the token “it”, the model needs to decide what “it” refers to.
For the token “it”:
Q_it = “I am looking for the thing this pronoun refers to”Other tokens expose keys:
K_dog = “I am an animal / possible subject”
K_ball = “I am an object / possible noun”The model compares:
Q_it · K_dog
Q_it · K_ballIf Q_it · K_dog is higher, then “it” attends more strongly to “dog”.
Then the output for “it” becomes a weighted mixture of the value vectors, especially:
V_dogSo the model enriches the representation of “it” with information from “dog”.
Why separate Q, K and V?
This is the key bit.
The model does not use the raw token embedding directly. It learns three different views of each token:
Q = XW_Q
K = XW_K
V = XW_VSame input X, different learned matrices.
Why?
Because “what I am looking for”, “how I should be matched”, and “what information I should contribute” are different jobs.
For example, the word “bank” might need to:
Q: look for context that disambiguates meaning
K: advertise that it is a noun, place, institution, river edge, etc.
V: contribute semantic content once selectedOne embedding cannot do all of that cleanly. QKV gives the model specialised subspaces for matching and information transfer.
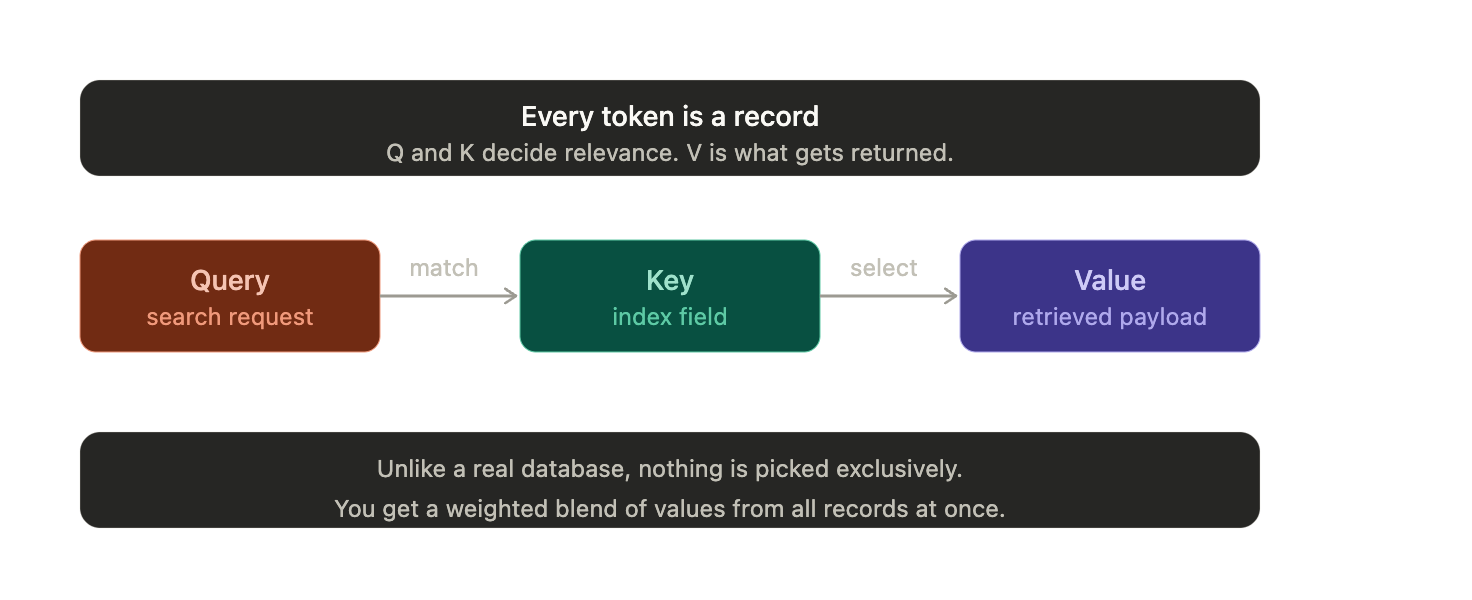
The database analogy
This is probably the most useful analogy:
Query = search query
Key = index / searchable metadata
Value = retrieved contentAttention is like searching a database where every token is a record.
Token = record
Key = searchable field
Value = payload
Query = search request from current tokenThe attention score says:
How relevant is this token’s key to my query?The output says:
Give me the values from the most relevant tokens.The important correction
People often say:
“Q asks a question, K answers it, V stores the answer.”
That is okay as a beginner analogy, but slightly misleading.
More accurately:
Q and K decide routing.
V carries content.Q and K determine where to attend.
V determines what information gets copied/mixed into the output.
One-line understanding
QKV attention is learned content-based routing: each token forms a query, matches it against other tokens’ keys, then pulls back a weighted blend of their values.
No spam, no sharing to third party. Only you and me.
Member discussion