LLM Scaling Thinking Smarter, Not Harder: How LLMs Can Learn on the Fly ...or how I learned to stop worrying and love inference-time scaling 05 Feb
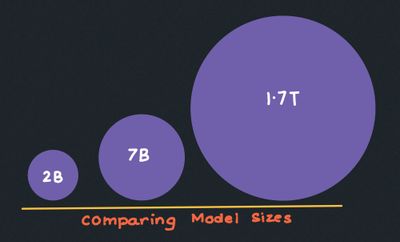
LLM Scaling How to think about LLM Model Size Breaking Down Parameters, Training Data, and Compute 03 Feb