
Understanding Generative UI

LLMs mostly talk. They respond in paragraphs. They summarise. They generate walls of text.
The paper Generative UI: LLMs are Effective UI Generators from Google Research argues that this is a waste of capability. If an LLM can reason, design, research, and code, then the natural interface should not be text. It should be a complete, functional user interface generated on the fly. I agree with this premise.
In this post, I break down the paper step by step using a structured Q&A format.
We start with the high level idea, then move down through the architectural details, the system prompt mechanics, and finally the low level technical implications.
Think of this as a guided walkthrough from concept to implementation.
What problem is this paper trying to solve?
The starting point is simple. Most LLM responses still collapse into text. Even strong models fall back to paragraphs. This is the wall of text problem.
The authors argue that this underuses model capability. Modern models can plan, design, research, and code. Yet our default interaction forces everything through text (often wrapped in markdown).
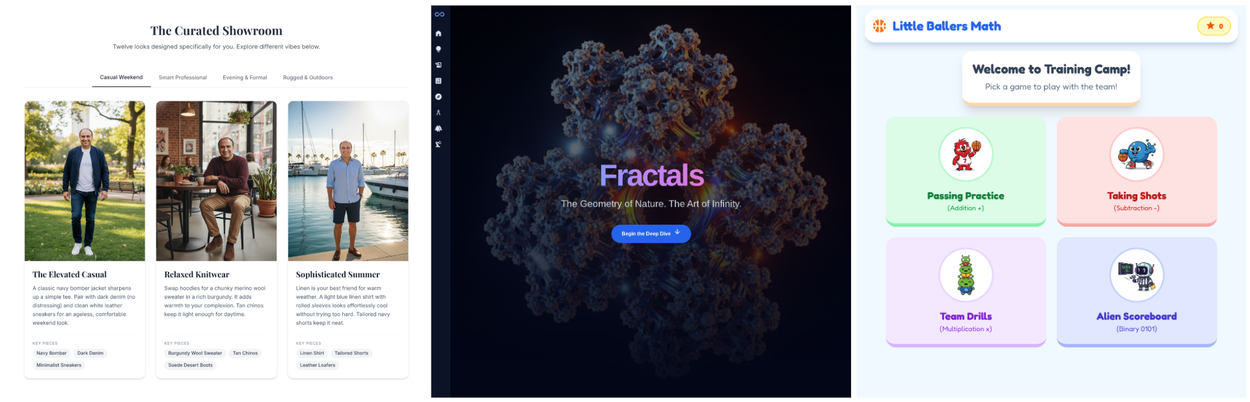
Their proposal is to let models generate complete interfaces. A short interactive experience. A mini application tailored to the question.
For example:
- A fractal explanation becomes a fractal explorer with sliders.
- A climate query becomes a small dashboard.
- A historical prompt becomes a timeline with images and map highlights.
In effect, the model behaves like a product manager, designer, and front end engineer in one generation.
The team validated the idea through human preference studies. They compared model-generated interfaces against markdown, plain text, top search results, and expert-built websites. Users consistently preferred the Generative UI pages over everything except the handcrafted ones. And in many cases the gap was small.
How does the system actually work end to end?
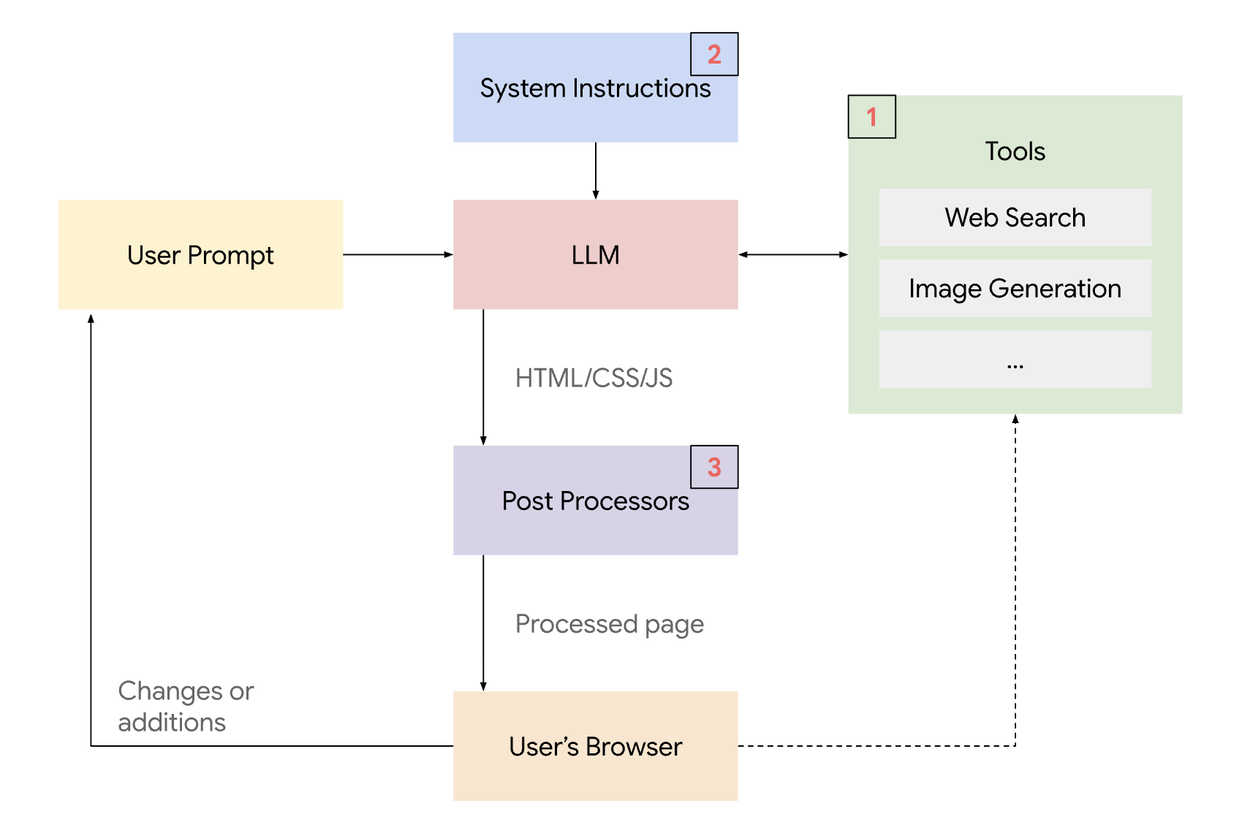
The system has four parts:
- A long, engineered system prompt
This tells the model how to think, plan, search, design, and code. - Tools
The model can call:
Web search, image search, image generation, video search. - Execution environment
The model outputs HTML, CSS, and JavaScript.
The browser renders the code directly. - Post processors
Lightweight scripts fix malformed tags or small issues.
The model is instructed to:
- Interpret the user request.
- Plan an experience: choose an interaction pattern, not just text.
- Plan a layout: sections, components, navigation.
- Fetch assets using search or generation tools.
- Produce complete HTML, CSS, and JS.
- Check its work.
- Output clean code.
All of this is triggered by a single user prompt.
Most systems generate a template or a component.This system generates a new complete interface per query. Every prompt becomes a bespoke micro experience.
What is inside the system instructions, and why do they matter?
The long system prompt is the backbone of the approach. It gives the model role, structure, and constraints.
The model is instructed to behave like a front end developer. It must think through the design before coding. It must avoid long text blocks and prefer interactive or visual elements where possible. It must fact check using search rather than guessing. And it must output code without commentary.
The constraints are precise:
- Wrap all output inside ```html fences.
- Only raw HTML should appear inside those fences.
- The document must include proper
<html>,<head>, and<body>tags. - Tailwind must be loaded from CDN.
- Images must use the
/image?query=or/gen?prompt=endpoints.
These rules keep the output predictable and renderable. They also reduce the number of failure cases the browser must handle.
The prompt also embeds basic design principles.
- Keep things readable.
- Use interaction where appropriate.
- Support the explanation with visuals.
- Break up content into focused components.
This combination leads to consistent behaviour. The model reliably avoids text dumps and produces interfaces that look designed rather than improvised.
What happens at a deeper technical level when the model follows these constraints?
The constraints create a stable environment for the model to integrate reasoning, design, and implementation.
Tailwind is an important enabler. It allows the model to express layout and styling through short utility classes rather than long CSS blocks. This reduces syntax errors and keeps styling consistent.
The model can also maintain coherence across style, layout, and content. If you specify a theme in the system prompt, the model adjusts colours, typography, and imagery to match. This is coordination across multiple modalities inside a single generation.
Hallucination is reduced because the model must call search for factual data. The planning stage makes this explicit. When the model outputs facts, they usually come from retrieved content rather than memory.
Failure modes still exist. Broken tags, missing scripts, occasional layout issues. The post processors handle some of these, but not all. Even so, the output quality is high enough for systematic evaluation.
How did the authors evaluate performance?
Their evaluation method is straightforward.
For each prompt, generate five outputs:
- A human-built page
- A Generative UI page
- A markdown LLM answer
- A plain text LLM answer
- The top Google search result
Then collect head-to-head human preferences.
The results are clear:
Markdown loses. 👎🏽
Plain text loses. 👎🏽
Search results lose more often than expected. 🫤 Generative UI wins most comparisons against all non-expert outputs.✨
The only consistent winner against Generative UI is the handcrafted page by a human expert. The gap is not wide. In many cases, the model-generated interface is viewed as similarly useful and easier to explore.
This is a meaningful shift. Interface generation is proving more effective than text for many categories of prompts.
What does this mean for AI engineers and product builders?
It suggests that the default LLM output channel is going to change.
Text will not be the primary surface for every task.
We will increasingly ask models to generate small interfaces rather than paragraphs. This shifts the focus from content-only prompting to interface-aware prompting.
It also shows that multi-stage behaviour can emerge inside one model. Planning, research, design, implementation, and review all happen inside a single structured prompt. No orchestration layer is needed.
Finally, it aligns with the direction of agentic systems. Agents need surfaces, not just text. They need ways to show reasoning, data, and next steps. Generative UI provides that surface dynamically.
The paper shows a turning point. Models no longer need to answer with paragraphs when they can generate full interfaces. Once you see a few good examples, text alone feels restrictive. This opens a new direction for interaction design. It also has direct implications for how we build agent-first UIs.
No spam, no sharing to third party. Only you and me.


Member discussion