
Why Context Is Not Enough



This post separates three ideas that often get blurred together: the current prompt, retrieval, and durable memory. Retrieval can fetch useful context into a prompt, and larger context windows can give a model more room to work, but neither one gives an agent a reliable way to decide what should be remembered, update stale facts, resolve contradictions, or carry state across sessions.
By the end of this post, you should have a clean mental model for why agent memory is more than a vector database attached to a chatbot. A serious memory system needs a write path, a read path, update and delete semantics, conflict handling, time awareness, and a way to turn scattered events into useful knowledge.
This series will move in three layers. This first post explains why context and retrieval are not enough, the second post walks through the main architecture patterns now emerging, and the third post looks at the frontier where memory becomes accumulated experience rather than passive storage.
The familiar failure mode
You tell an assistant you do not eat dairy, and a few weeks later it recommends a cheese-heavy recipe. You tell a coding agent that your team uses a specific test runner, and the next day it suggests commands for a different one. You tell a support bot you have already restarted the device, and it asks you to restart it again.
In each case, the problem is not that the model forgot how to reason. The problem is that the application gave important information only one fragile place to live: the current prompt. A model can sound fluent inside one interaction while having no durable memory of what mattered before, and as soon as the conversation changes, the task stretches across time, or the user returns later, that illusion starts to break.
Most agent applications still treat context as something assembled at request time rather than something managed over time. That works for demos, short sessions, and narrow question answering, but it falls apart when the product promise includes continuity, personalisation, learning from past attempts, or long-horizon work.
The current prompt is a temporary workspace
A prompt is a workspace that is assembled for a single request. It may include system instructions, recent messages, tool outputs, retrieved chunks, and the user's latest input, but unless your application writes something somewhere durable after the response, the prompt disappears as soon as the request is complete.
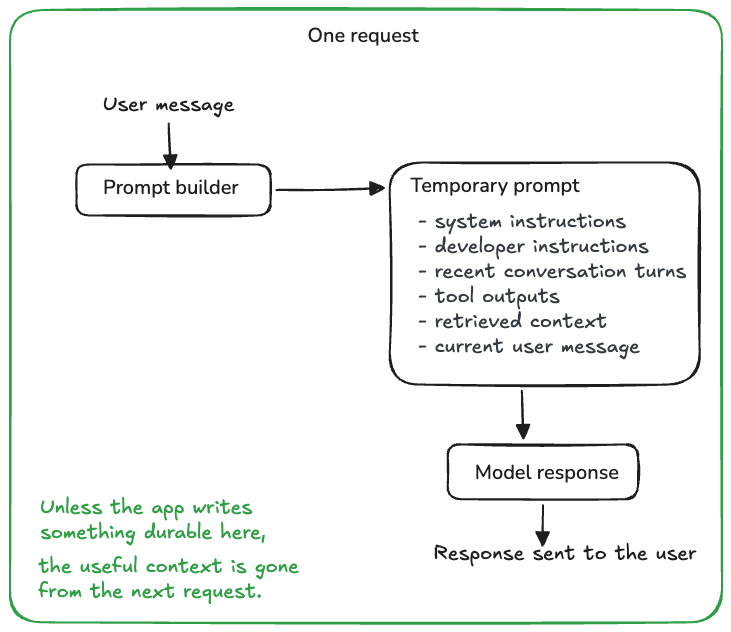
This is why a chatbot can feel coherent for ten minutes and then feel strangely amnesic the next day. The model is not carrying state forward on its own. The application has to decide what should survive, where it should be stored, how it should be updated, and when it should be recalled.
Larger context windows buy room, not continuity
A larger context window is useful because it lets the model inspect more information at once. It can reduce the pressure to summarise aggressively, and it can help with long documents, longer conversations, and more complex tool traces.
However, a larger window does not solve durable memory because it still works only with what you put into it for the current request. If the relevant fact came from a session six weeks ago, and your application did not store and retrieve it, the model cannot use it. If the prompt contains both an old fact and a newer correction, the model needs help knowing which one is valid. If the user asks a question that depends on a long chain of events, simply stuffing more text into the prompt may bury the signal in noise.
A million-token window can delay the cliff, but it does not remove the need for a memory architecture.
Retrieval is useful, but retrieval is not memory
Developers often add retrieval to patch the gap. Documents, notes, and conversations are chunked, embedded, and stored in a vector database, and at request time the system retrieves the most similar chunks and places them into the prompt.
That pattern is valuable, especially for document-grounded question answering, but it is still a context assembly technique. The retrieved chunks are temporary inputs, not managed memories.
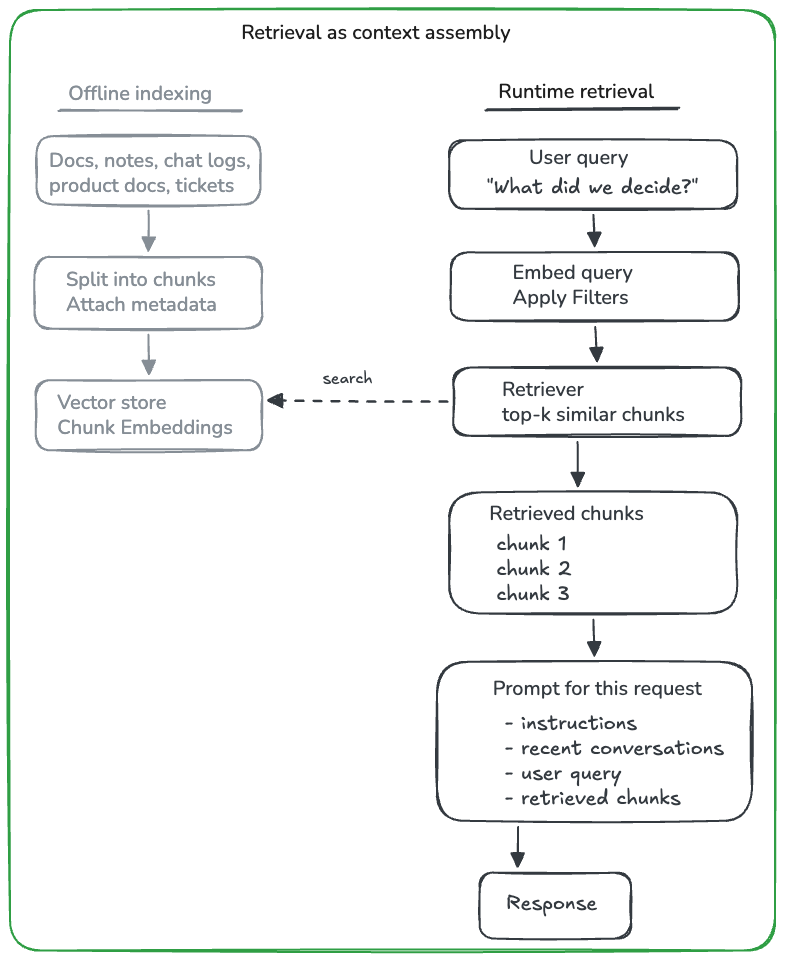
RAG answers the question, "What external information should I place into this prompt?" Memory has to answer a larger set of questions: "What should be stored from this interaction, what should be updated, what should be forgotten, what changed over time, and what is relevant now?"
Where RAG breaks when you use it as memory
The simplest way to see the gap is to look at a user fact that changes over time.
Conversation history stored as chunks
Jan 04 "I live in Manchester and usually work from home."
Mar 18 "I moved to Bristol, so update my local recommendations."
Apr 02 "I need somewhere nearby for dinner tonight."
RAG-style retrieval
Query: "Find a nearby dinner place for me."
|
v
Similar chunks returned:
1. "I live in Manchester..."
2. "I moved to Bristol..."
3. unrelated restaurant chat
|
v
Prompt now contains conflicting facts, but the system has not encoded:
- which fact supersedes the other
- when each fact was valid
- whether Manchester should be deleted or archived
- whether Bristol should be promoted to current profile state
A memory system should treat the March statement as an update to a durable user profile, while a retrieval system may simply return both statements and hope the model resolves the conflict. Sometimes the model will infer correctly, but hope is not architecture.
This issue shows up in several forms:
- No write path: RAG usually indexes documents or messages, but it does not decide which new facts deserve to become memory.
- No update semantics: a new fact may contradict an older fact, yet both remain in the store unless the application manages conflicts.
- No deletion semantics: users may change preferences, revoke information, or request deletion, and a memory system needs to support that directly.
- Weak time awareness: similarity search does not automatically understand recency, validity periods, or event order.
- Redundant recall: top-k retrieval can return several near-duplicate chunks instead of the one decisive update.
- Prompt pollution: irrelevant or stale chunks can crowd out the information the agent actually needs.
RAG is still useful, but it should be one component of the memory stack rather than the whole story.
What durable agent memory adds
A memory system needs both a write path and a read path. The write path decides what should survive from an interaction, and the read path decides what should be brought back for the current task.
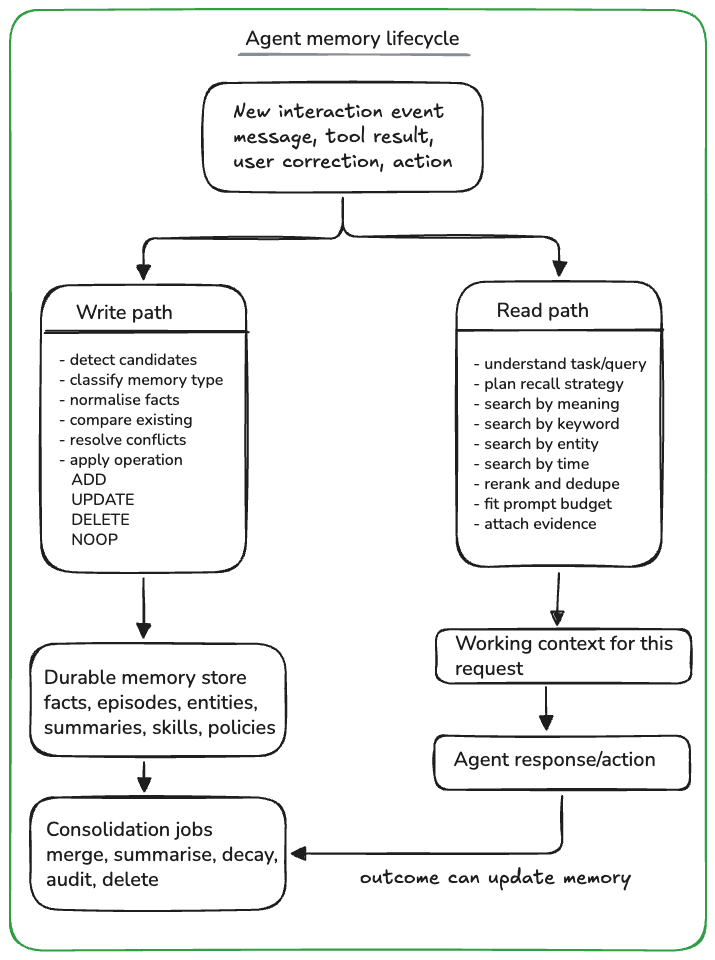
This lifecycle is what turns a stateless interaction into a relationship with continuity. The system can remember that the user moved to Bristol, update the current location, preserve the older Manchester fact as history if needed, and retrieve the right fact later without filling the prompt with stale context.
Memory is not one thing
When people say "agent memory", they often mean several different capabilities at once. It helps to separate them because each one suggests a different architecture.
| Capability | What it means | Example |
|---|---|---|
| Recall | Bring back relevant prior information | User prefers Python |
| Update | Revise stale facts | User moved city |
| Consolidation | Turn events into stable knowledge | Repeated corrections become a preference |
| Temporal reasoning | Respect order and validity | Current employer, old employer |
| Procedural reuse | Reuse successful actions | Known deployment steps |
| Governance | Control retention and deletion | User asks to forget data |
A basic vector store can help with recall, but the other capabilities require more structure.
How this series will build the idea
This post is the foundation. It argues that context is temporary, retrieval is not enough, and durable memory needs explicit write, read, update, and consolidation mechanisms.
The next post will compare the architecture patterns that have emerged in the last two years. We will look at extracted fact memory, temporal graphs, hierarchical memory, typed semantic memory, query-aware indexing, and hybrid routing, and we will focus on the design choices that matter when you are building a real product.
The final post will move from memory as storage to memory as accumulated experience. We will look at reflection, self-evolving memory, activation-based graph recall, multimodal memory, and benchmarks that test whether agents can actually use memory to act better over time.
The mistake is to treat memory as a bigger prompt or a smarter search query. Prompt context helps the model reason now, and retrieval helps the model find external information now, but agent memory is about continuity across time. Once you design for continuity, the architecture changes: you need to decide what gets remembered, what gets revised, what gets forgotten, and what should be recalled for the task in front of the agent.
No spam, no sharing to third party. Only you and me.








Member discussion