
How Modern Agent Memory Architectures Work



Part 1 argued that context is not memory. A prompt is temporary workspace, and retrieval can bring useful information into that workspace, but neither gives an agent continuity across sessions.
This post moves from the why to the how. We’ll compare the main architecture patterns emerging across modern agent memory systems by looking at the design choices that matter: what gets stored, how stale information is updated, how recall is planned, how conflicts are handled, and what latency or complexity each approach introduces.
The core idea is simple: useful memory is not a pile of old messages. Modern systems extract facts, preserve episodes, build semantic structure, version information that changes, consolidate related events, and retrieve through multiple signals rather than relying only on vector similarity.
By the end, you should be able to look at a memory architecture and understand what kind of agent it actually suits.
Start with the product promise
Before choosing a memory architecture, start with the promise your agent is making.
A personal assistant promises continuity, so it should remember preferences, constraints, past plans, and changes over time. A coding agent promises accumulated project understanding, which means it should remember the repository layout, test commands, flaky dependencies, and failed attempts. A support agent promises case continuity, so it should remember what the user has already tried, which device they own, and what the previous agent or workflow concluded.
These are different promises, so they lead to different memory requirements. A chatbot may mostly need user facts and preferences, while a coding agent needs procedural memory, environment observations, and task outcomes. A long-horizon worker needs memory tied to actions and feedback, not just stored conversation snippets.
That is why it is misleading to ask, “What is the best memory system?” The better question is: “What kind of continuity does this product need to provide?”
The shape of an agent memory system
Most serious memory systems can be understood as a combination of three things: a write path, a read path, and a maintenance loop. The write path decides what should become memory. The read path decides what should come back into the current task. The maintenance loop keeps memory useful as it grows.
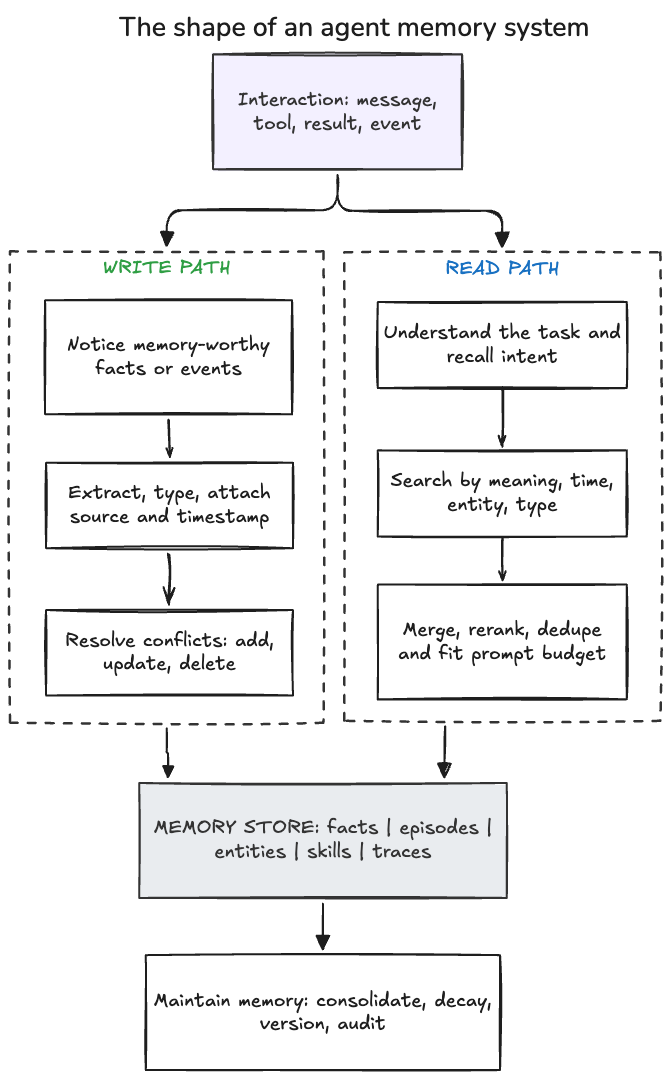
The important shift is that memory starts before retrieval. If the system writes poor memories, retrieval has little chance of rescuing it later. If it never updates stale information, retrieval can actively make the agent worse by bringing old facts back into the prompt.
Four useful kinds of memory
The vocabulary comes partly from cognitive science, but it maps cleanly onto engineering concerns.
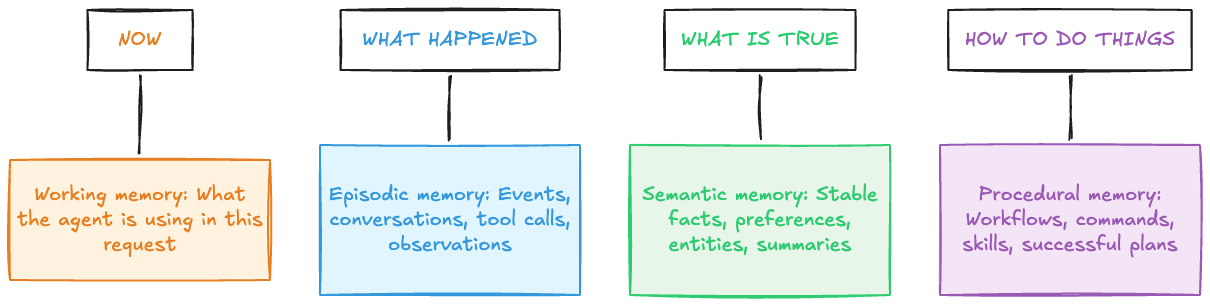
A good assistant usually needs more than one kind. If a user says, “I moved from Manchester to Bristol,” the statement itself is episodic memory because it happened at a particular point in time. The current location becomes semantic memory, or more precisely user-state memory because it represents what is true now. The old location may still be useful as historical context, but it should not be treated as the current fact.

If a coding agent learns that pnpm test --filter api is the right command for a repository, that belongs closer to procedural memory because it tells the agent how to do something reliably in that environment.
Pattern 1: extracted fact memory
The most practical starting point is extracted fact memory. Instead of storing every message, the system turns conversation into compact facts, compares those facts with existing memory, and stores the useful updates.
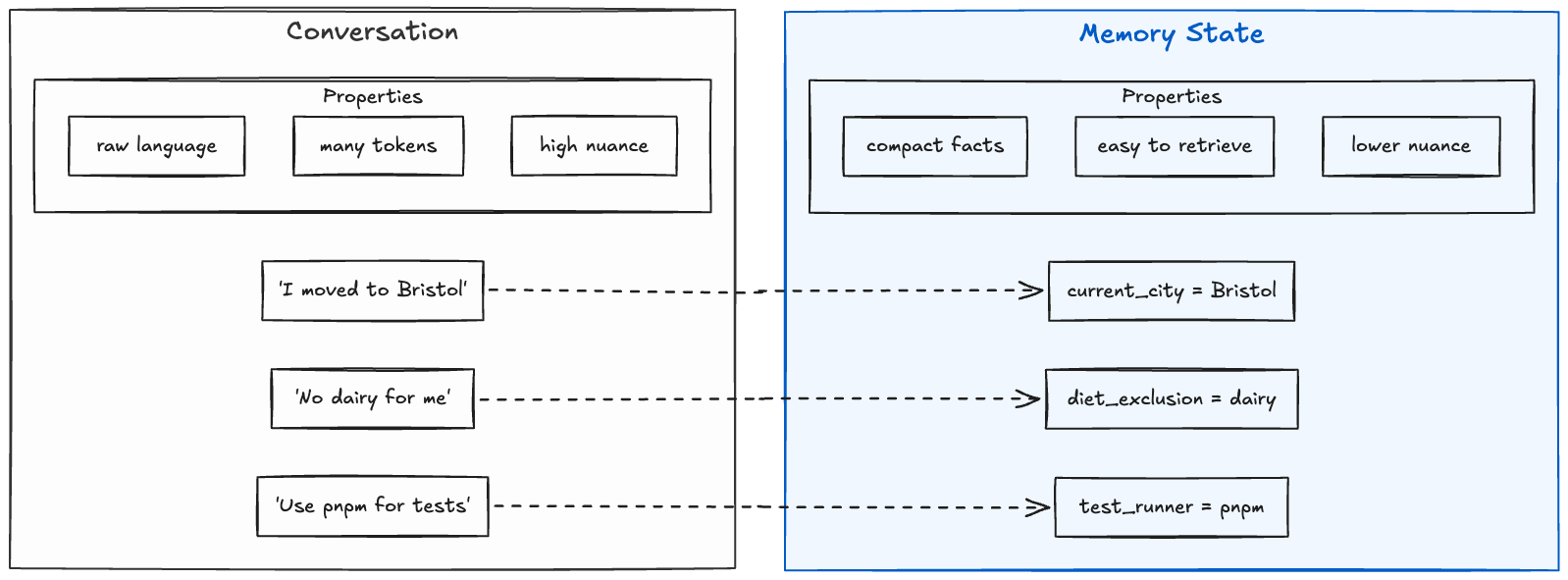
This pattern is attractive because it is simple, cheap, and easy to inspect. Mem0 is a prominent example. It extracts salient facts, applies operations such as ADD, UPDATE, DELETE, and NOOP, and retrieves memories through multiple signals.
The hard part is not extraction alone, because the system also has to decide what happens when new information conflicts with old information.
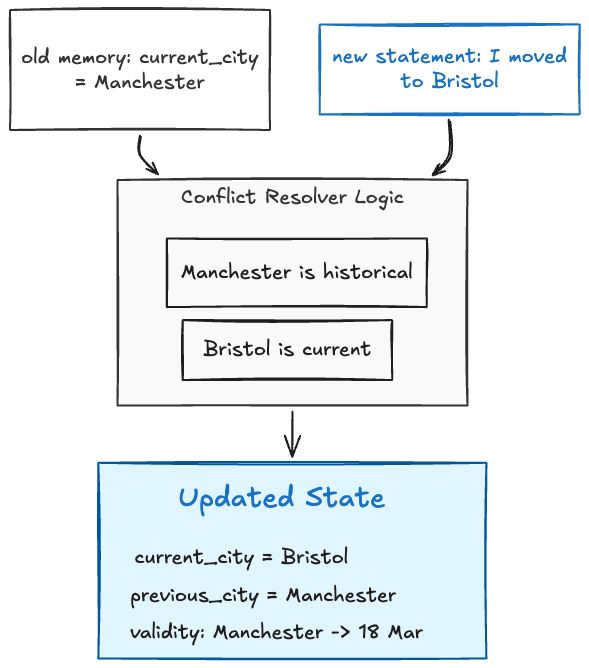
The weakness is that extracted facts can lose nuance. If the extractor is too aggressive, it may flatten a rich event into a brittle statement. If it is too conservative, the memory store fills with clutter. Extracted fact memory works well for personalisation and chat continuity, but it needs source tracking, confidence, timestamps, and conflict handling if it is going to survive real use.
Pattern 2: temporal graph memory
A temporal graph treats memory as entities, relationships, and events over time. Instead of asking only, “What text is similar to this query?”, the system can ask, “Which entity is connected to this user, what changed, and when was that fact valid?”
This is useful when the domain contains people, projects, tickets, documents, locations, products, accounts, or workflows that change over time.
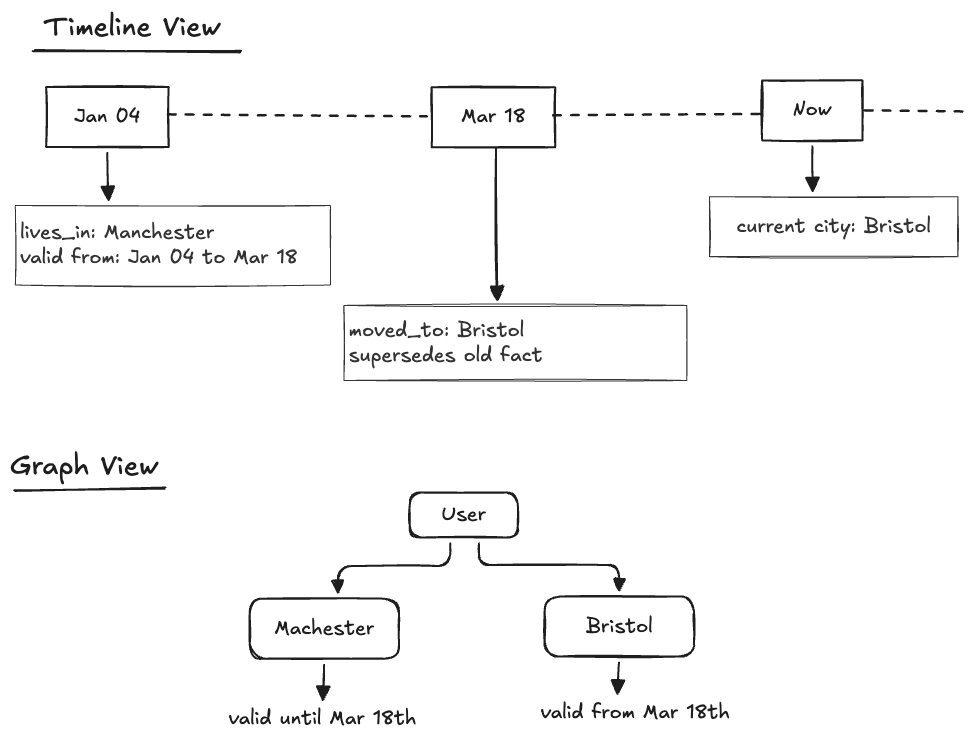
Zep is a prominent example of this pattern. It builds a temporally aware graph from unstructured conversation and structured business data, and it separates raw episodes from semantic entities and higher-level communities.
The strength is relational and temporal reasoning. The trade-off is operational complexity, because graph construction, entity resolution, and query planning can become expensive. This architecture makes more sense for enterprise assistants, customer support, internal knowledge systems, and agents that need to connect many changing entities over time.
Pattern 3: hierarchical memory
Hierarchical systems recognise that raw messages are too small and global summaries are too blunt. They organise memory into levels, so the agent can retrieve a compact high-level structure first and drill into details only when needed.
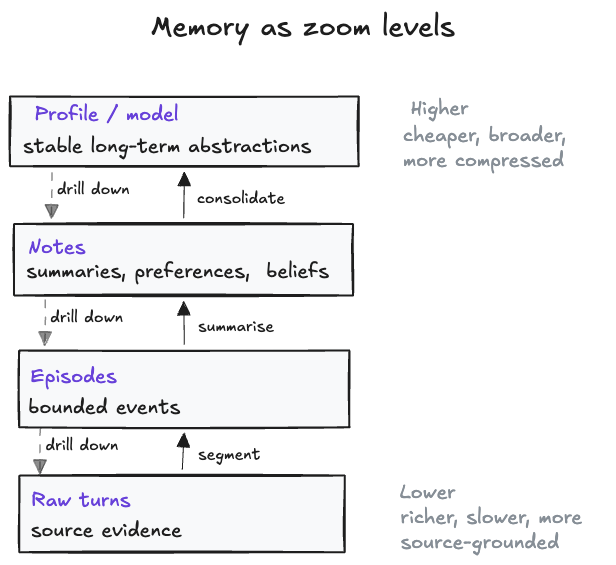
In practice, this often looks like raw turns being grouped into episodes, episodes being turned into notes, and notes being consolidated into a stable user or task profile.
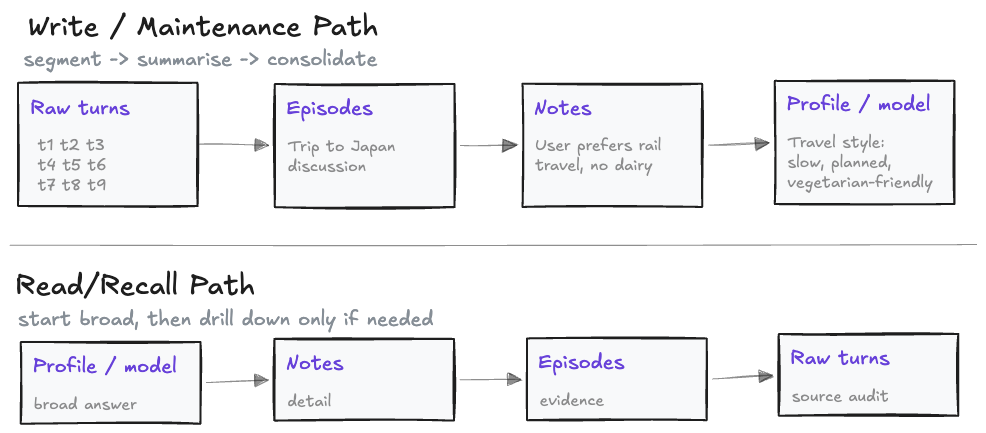
xMemory, Membox, HiMem, and TiMem all explore this direction from different angles. xMemory argues for decoupling details before aggregation. Membox preserves topic continuity through memory boxes and timeline traces. HiMem links episode memory with note memory. TiMem uses a temporal memory tree that consolidates observations into higher-level user profiles.
This approach is useful when the agent needs long-term continuity without dragging every old message into the prompt. A travel-planning agent may not need every message about a trip, but it needs the final destination, dates, constraints, and unresolved decisions. A coding agent may not need every failed command, but it does need the final working setup and a record of what failed.
Pattern 4: typed semantic memory
Typed memory starts from the idea that not all memories should be stored, updated, governed, or retrieved in the same way. A dietary preference, a current address, a project decision, a tool command, and a failed hypothesis have different lifecycles.
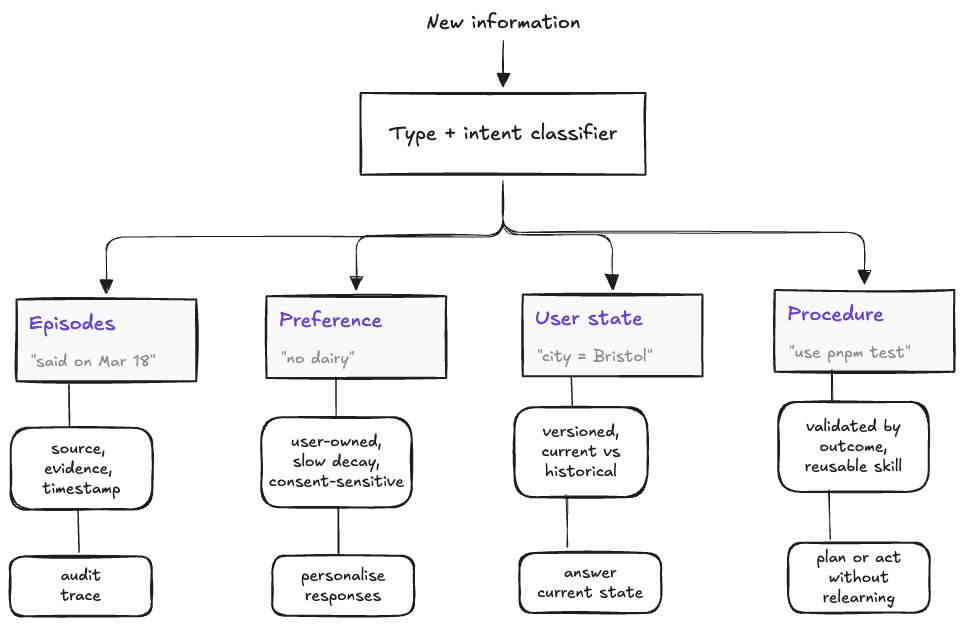
Memanto is a clear example because it uses predefined memory categories, temporal versioning, and conflict resolution. The point is not merely classification. The point is that type controls lifecycle.
A preference may be user-owned and editable. A location may be versioned and time-aware. A procedure may be kept only if it has worked before. A failed hypothesis may be useful for a coding agent but irrelevant for a recipe assistant.
Typed memory works particularly well when the product domain has stable concepts. A health assistant, enterprise support agent, or coding agent can benefit from explicit types because they reduce ambiguity and make governance easier. The risk is rigidity, since a fixed schema may not fit a new domain without careful extension.
Pattern 5: multi-strategy recall
Modern systems increasingly avoid a single retrieval method. Semantic search is useful, but names, IDs, dates, exact commands, and causal relationships often need keyword search, entity filters, graph traversal, or temporal constraints.
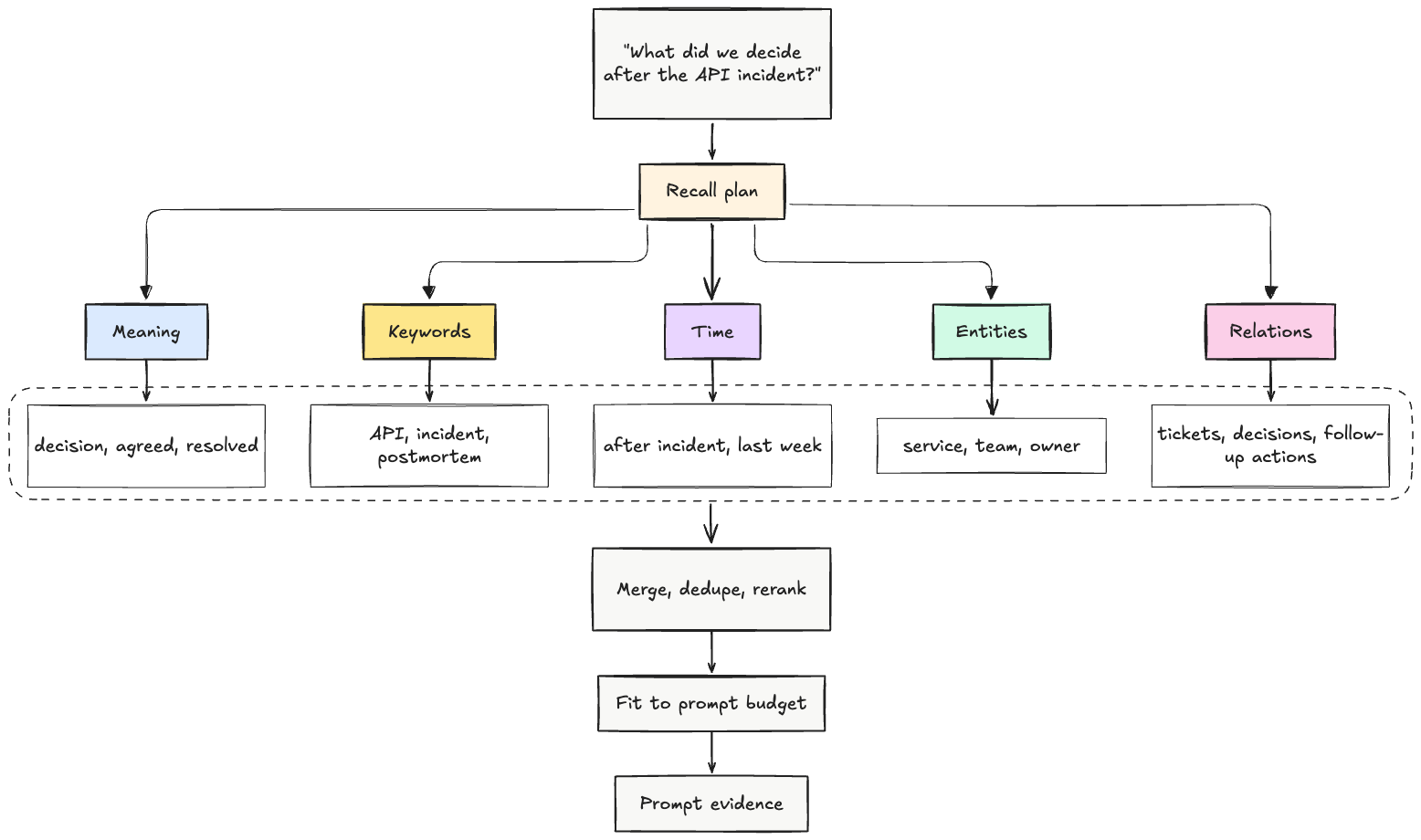
SwiftMem optimises retrieval through query-aware indexing, while Hindsight treats memory as a structured substrate for retain, recall, and reflect operations. The broader lesson is the same: memory retrieval has to be fast enough for interactive agents and precise enough for long-horizon work.
A system that retrieves the right fact in 30 seconds is too slow for a user-facing assistant. A system that responds quickly but retrieves stale or irrelevant facts is worse than no memory at all.
Same problem, different architectures
The easiest way to see the difference between patterns is to run the same memory problem through each one.
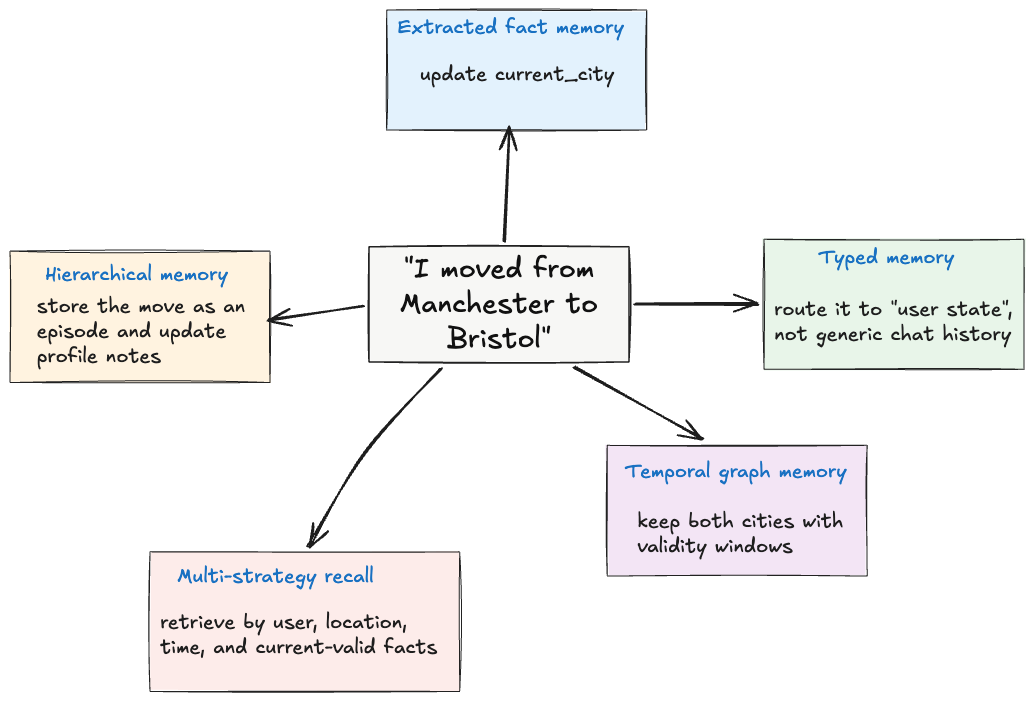
None of these answers is universally correct. They reflect different product needs. A simple chatbot may only need the extracted fact. A customer support assistant may need the temporal graph because previous addresses, devices, and plans still matter. A travel planner may need the profile update. A regulated product may need typed memory so users can inspect and delete specific categories.
How do you evaluate design choices?
When evaluating a memory architecture, the useful questions are rarely about which system is best. The right answer depends on the agent.
What gets written?
Do you store raw messages, extracted facts, summaries, entities, skills, task outcomes, or all of the above? Raw logs preserve detail but grow quickly, while extracted facts are compact but can lose nuance.
Who decides what becomes memory?
A developer rule may be predictable, but it can miss subtle facts. A model-based extractor may be flexible, but it can hallucinate or overwrite too much. A learned controller may adapt, but it is harder to debug.
How are conflicts handled?
If the user changes city, employer, diet, toolchain, or project decision, does the system overwrite, version, delete, or keep both facts with validity windows?
How does recall work?
Does the system retrieve by semantic similarity only, or does it also use keywords, time, entities, graph structure, memory type, and task intent?
How is memory consolidated?
Does the system periodically merge related events into stable knowledge, or does it leave every event as an independent fragment?
How is governance handled?
Can the user inspect, edit, delete, or scope memory? Can the product explain why a memory was used? Can the system avoid storing sensitive data that should never persist?
How is memory evaluated?
A useful memory system should be evaluated on more than recall accuracy. It should be tested for freshness, conflict resolution, latency, token cost, source traceability, deletion correctness, and whether retrieved memories actually improve task success. A retrieved memory that is plausible but stale is not a success.
Choosing a memory pattern
Here is a practical way to reason about the choice.
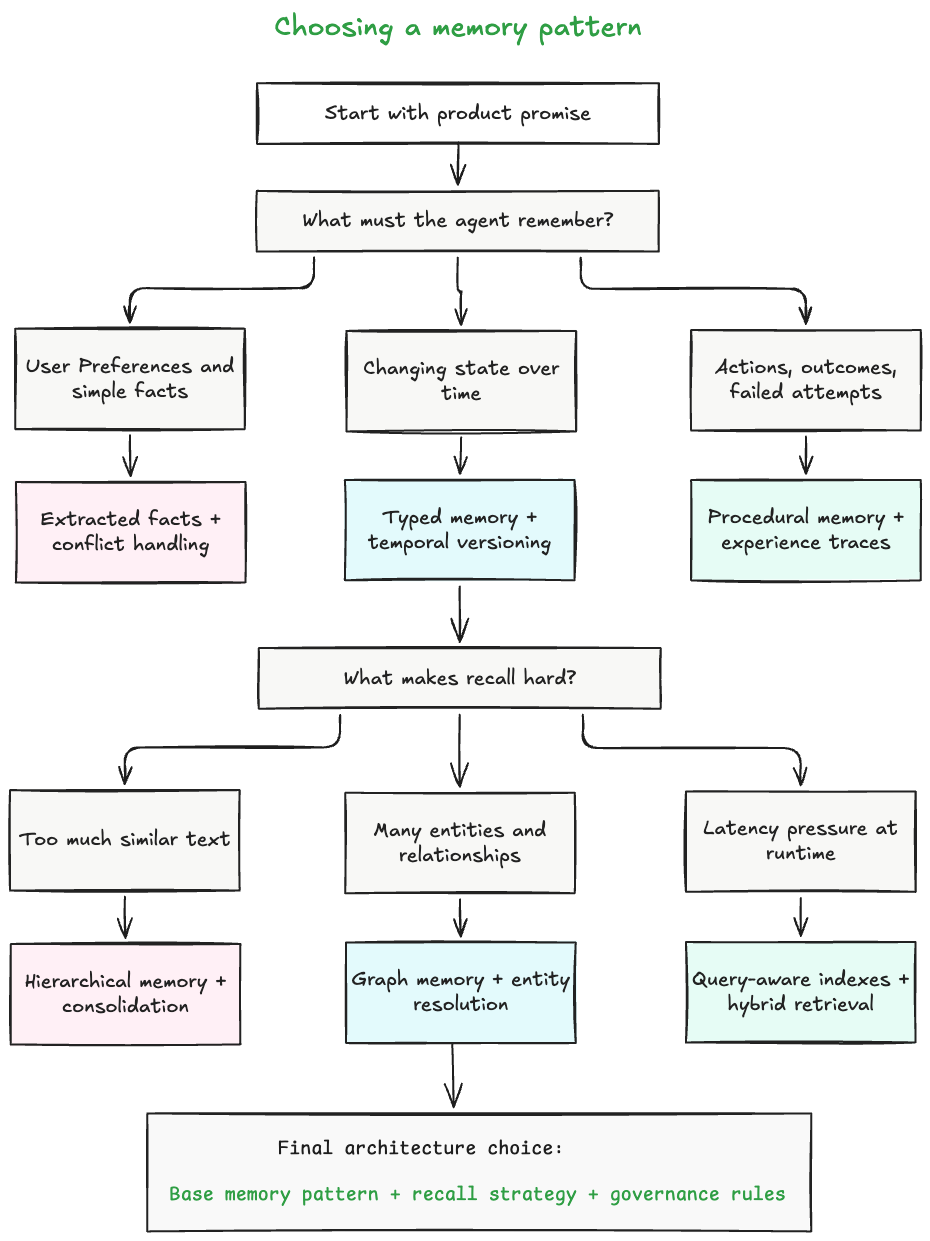
A simple chatbot can start with extracted facts and conflict handling. A personal assistant usually needs typed memory and temporal versioning. A support bot benefits from graph memory and case timelines. A coding agent needs procedural memory and outcome tracking. A research agent usually needs hybrid retrieval and strong source grounding. A multimodal assistant needs memory that can preserve more than text.
This is not a maturity ladder where every system must become a graph, then a hierarchy, then a learned memory controller. It is a set of trade-offs, and the best architecture is the simplest one that supports the product promise without making latency, governance, or debugging impossible.
The big shift in agent memory is from retrieval over old text to managed state over time. Once you see memory as state, the architecture becomes clearer. You need to decide what gets written, how it changes, how it is searched, how it is compressed, and how it is governed.
Part 3 will look at the frontier, where memory goes beyond recalling facts. Advanced systems are starting to reflect on stored evidence, revise beliefs, learn from task outcomes, and use memory to decide what action to take next.
No spam, no sharing to third party. Only you and me.
Member discussion