LLM Scaling
Fitting LLMs on Self-Hosted GPUs
How much VRAM does your LLM need, and which GPU should you actually rent? A free calculator covering DeepSeek, Llama, Mixtral on H100, B200, A100.
How "Thinking" Models Actually Work
Lilian Weng's Why We Think is a survey of test-time compute and chain-of-thought reasoning. Here's what I pulled out of it.
LLM Scaling
Thinking Smarter, Not Harder: How LLMs Can Learn on the Fly
...or how I learned to stop worrying and love inference-time scaling
LLM Scaling
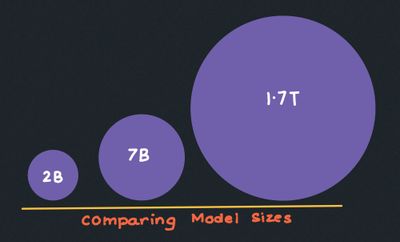
How to think about LLM Model Size
Breaking Down Parameters, Training Data, and Compute