
The Frontier of Agent Memory: From Recall to Experience



In Part 1, I explored the idea that context is not memory. A prompt is temporary workspace, and RAG is a useful way to bring external information into that workspace, but neither gives an agent durable continuity across sessions.
In Part 2, I looked at how modern agent memory systems are starting to solve that problem architecturally. We covered extracted fact memory, temporal graph memory, hierarchical memory, typed memory, and multi-strategy recall. The common thread was that useful memory is not a pile of old messages. It is managed state over time.
If Part 2 was about the shape of memory stores, this final post in the series is about what happens after memory starts accumulating. Long-running agents do not just need to write and retrieve memories. They need to maintain them, consolidate them, resolve contradictions, learn from outcomes, and use past experience to make better decisions in the future.
That is where agent memory becomes more interesting. It stops being just a retrieval problem and becomes the mechanism through which agents learn from prior interactions, avoid old mistakes, and carry useful context into future work.
The first generation of agent memory was mostly about recall: can the agent retrieve something useful from previous interactions? The frontier is moving beyond that. The next generation of memory systems will need to revise beliefs, clean up stale memories, consolidate repeated signals, learn from failed actions, work across tools and modalities, and use memory to decide what to do next.
That shift changes the architecture. Memory is no longer just a store that sits beside the prompt. It becomes part of the agent’s learning loop: a way to accumulate evidence, turn some of it into durable knowledge, preserve the original source when needed, and keep that knowledge current over time.
By the end of this post, you should have a practical mental model for where agent memory is going: from recall, to reflection, to offline consolidation, to memory-guided action.
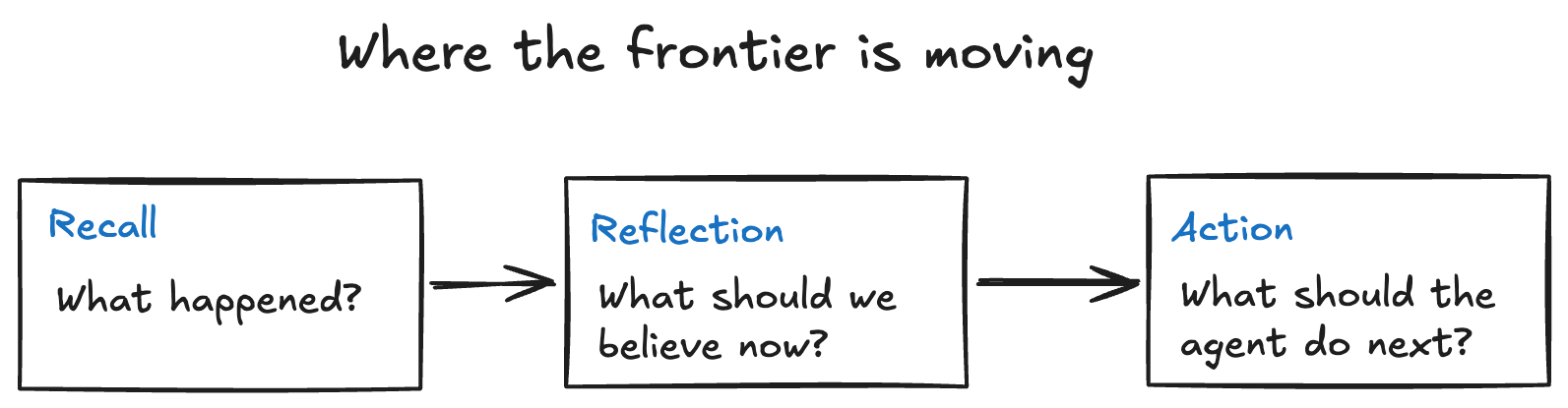
From memory to experience
An experienced colleague does not just remember notes. They know which assumptions have gone stale, which workflow failed last time, which constraints matter, and which shortcut is likely to work again. They can also explain why they believe something, and they can update that belief when new evidence arrives.
That is the direction agent memory is heading.
The goal is no longer only to answer, “What did the user say before?” The harder goal is to answer, “Given everything that has happened, what should the agent now know, and how should that change what it does?”
That requires a richer memory lifecycle.
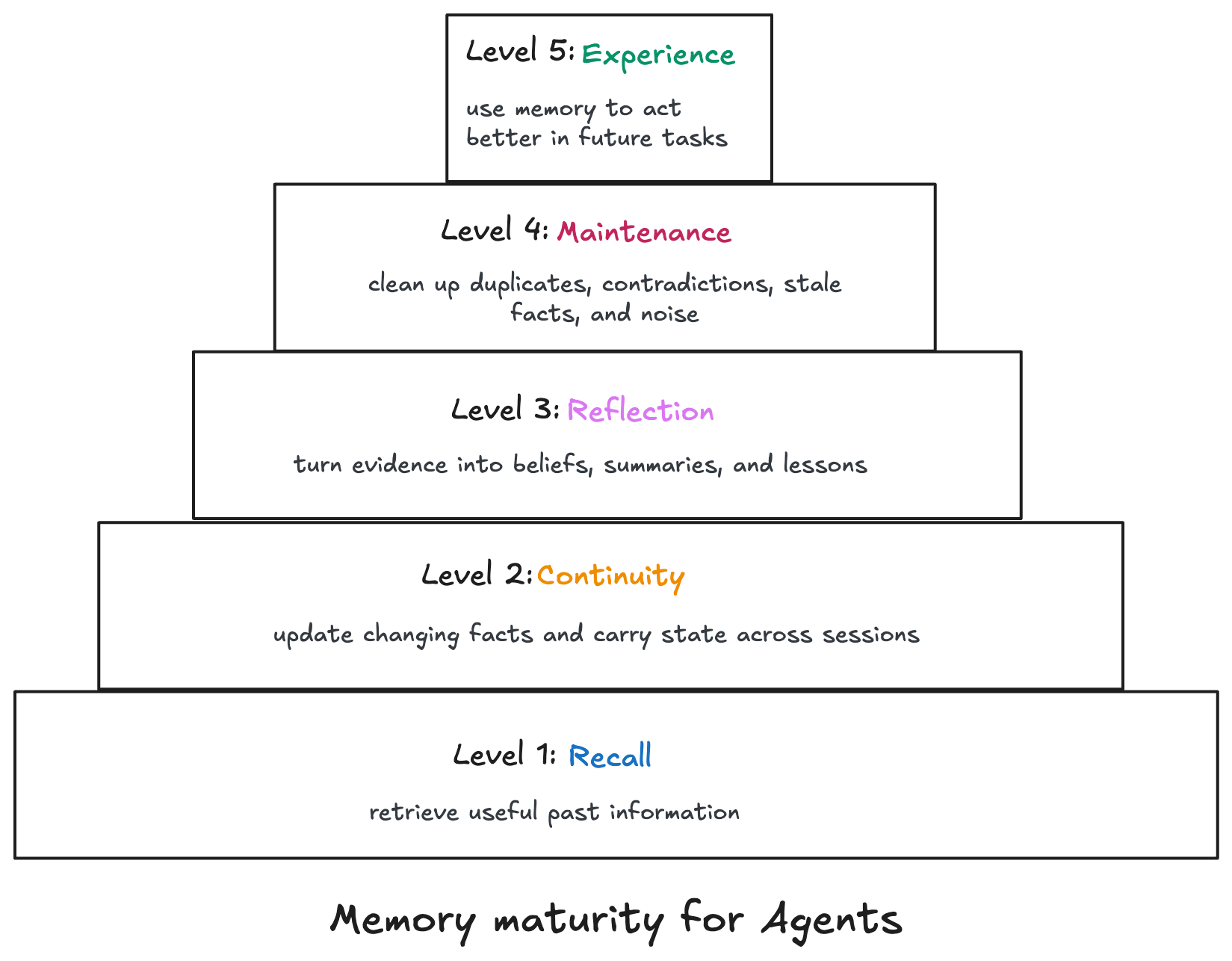
The rest of this post walks through the frontier areas that sit above basic recall: reflection, associative memory, continuum memory, offline consolidation, memory-guided action, scale, and multimodal memory.
Frontier 1: retain, recall, reflect
A useful framing for modern agent memory is the cycle of retain, recall, and reflect.
Retain means the system stores evidence from interactions. Recall means it retrieves relevant evidence later. Reflect means the system interprets that evidence and updates higher-level beliefs or summaries.
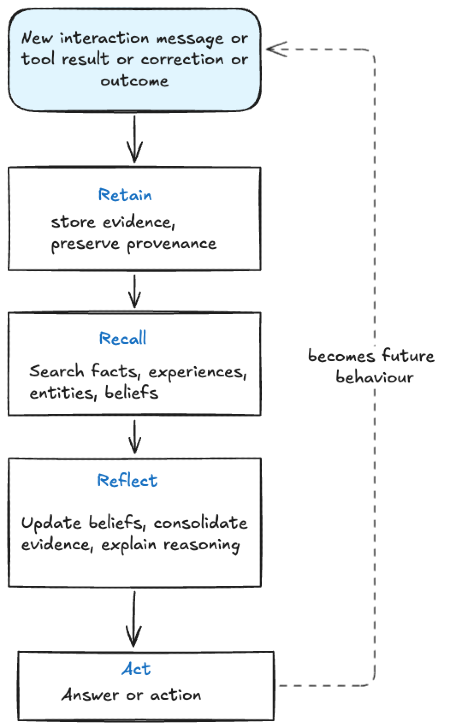
The important move is separating evidence (in Retain) from inference or deduction (in Reflect).
A raw event might say, “The user declined an 8am meeting twice.” A reflected belief might say, “The user probably prefers meetings after 10am.” Those two memories should not be treated as the same thing because one is evidence and the other is interpretation.
Evidence layer
--------------
- User declined 8am meeting on Monday.
- User declined 8:30am meeting on Wednesday.
- User said school drop-off makes mornings hard.
Reflection layer
----------------
- User likely prefers meetings after 10am.
- Confidence: high
- Sources: three events
- Scope: scheduling only
This distinction matters because beliefs should be revisable. If the user later says, “I can do early meetings on Fridays,” the system should not blindly apply the old preference everywhere. It should update the belief, preserve the evidence, and narrow the scope.
That is the difference between memory as a collection of facts and memory as a managed model of the world.
Frontier 2: living graphs and spreading activation
Flat retrieval asks which memory is most similar to the query. That is useful, but it can miss related memories that do not share obvious wording.
A more associative approach is to model memory as a graph where one memory can activate nearby memories. This is the idea behind spreading activation style systems such as SYNAPSE.
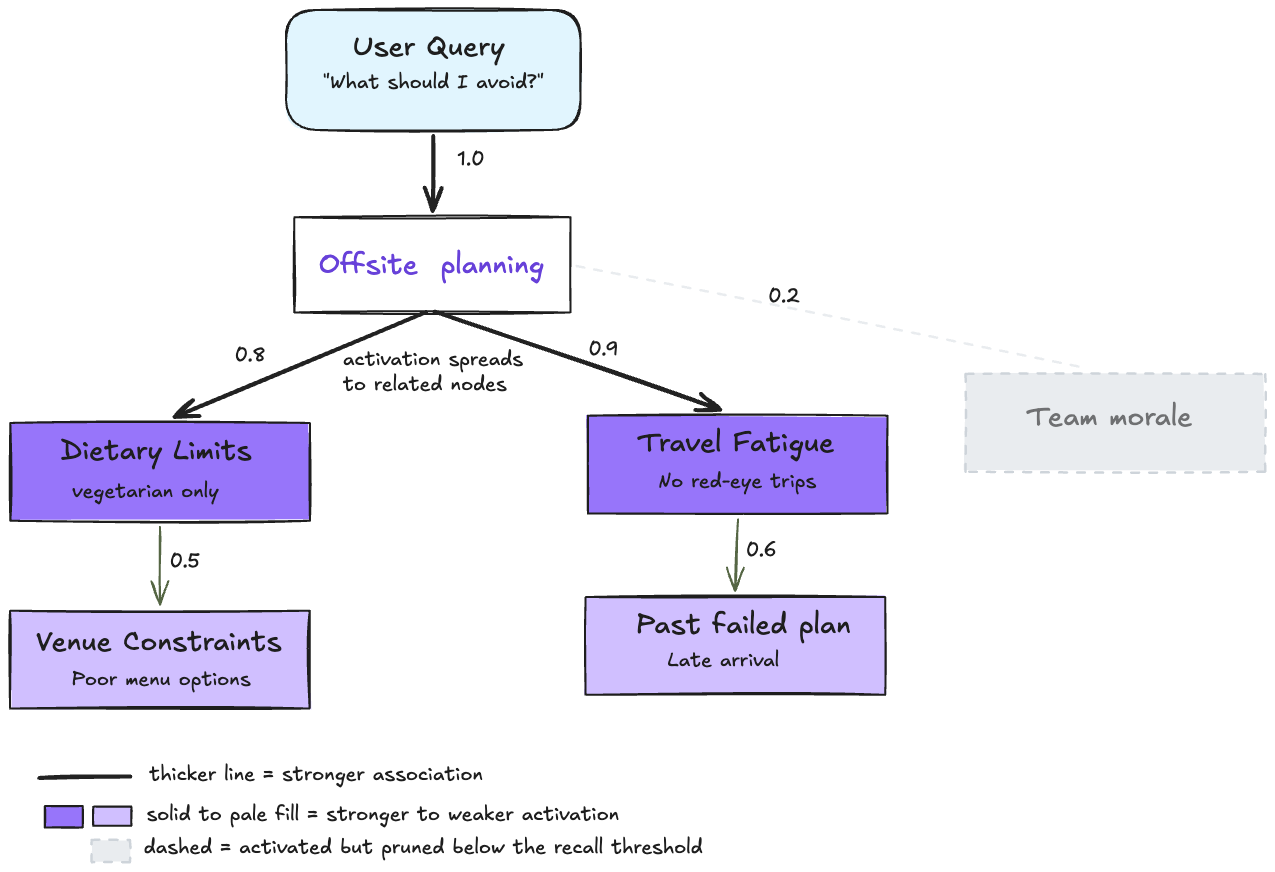
Instead of asking only which chunk is closest to “offsite”, the system can activate connected memories about travel fatigue, dietary constraints, venue constraints, and previous failed plans. The useful context emerges from the cluster.
The risk is noise. If activation spreads too far, the prompt fills with irrelevant memories. If it is too narrow, the system misses context. This is why these systems need temporal decay, inhibition, ranking, and prompt budgeting.
The architectural lesson is that some forms of recall need relationships, not only similarity.
Frontier 3: continuum memory
A lot of memory systems behave like lookup systems. Something is written, then something is retrieved. Continuum memory reframes this as an ongoing process.
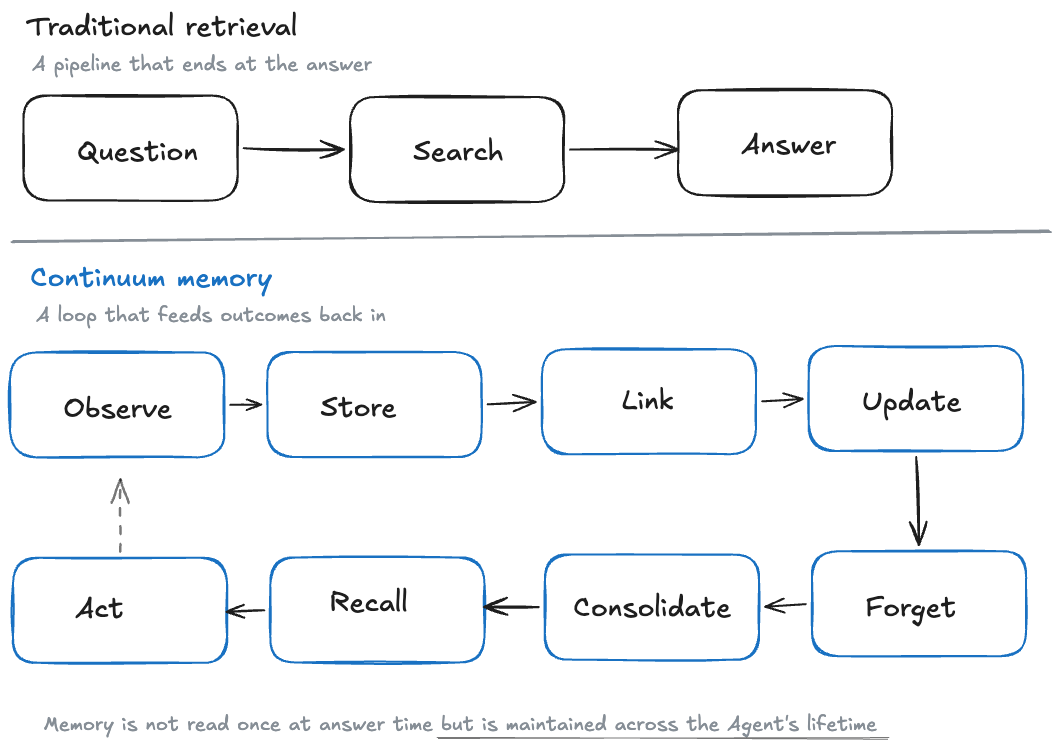
The key shift is that memory is not only used at answer time. It is maintained across the lifetime of the agent.
To do that well, the system has to track what changed, what stayed true, what was contradicted, what should decay, what should become stable knowledge, and what should remain as raw evidence.
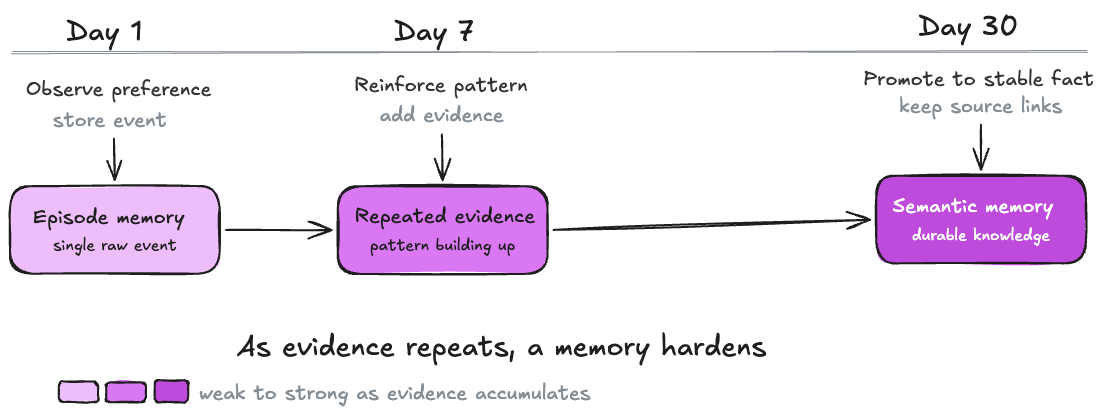
This is where memory starts to look less like search and more like state management. You are not just retrieving from the past. You are managing a changing model of the user, the task, the environment, and the agent’s own experience.
Frontier 4: dreaming and offline memory consolidation
One of the most interesting emerging product patterns is offline memory maintenance.
During normal work, agents tend to write memories incrementally. That is useful because the memory store evolves as the agent operates, but incremental writes are local. Over many sessions, the store can accumulate duplicates, stale facts, partial observations, weak summaries, and contradictions.
This creates a second problem: the memory store itself needs maintenance.
Anthropic’s Claude Dreams (currently in beta) feature is a concrete example of this pattern. In the Claude Managed Agents API, a dream is an asynchronous job that reads an existing memory store and past session transcripts, then produces a new, reorganised memory store. The goal is to merge duplicates, replace stale or contradicted entries with newer values, and surface new insights. Importantly, the input store is not modified, so the output can be reviewed, used, or discarded.
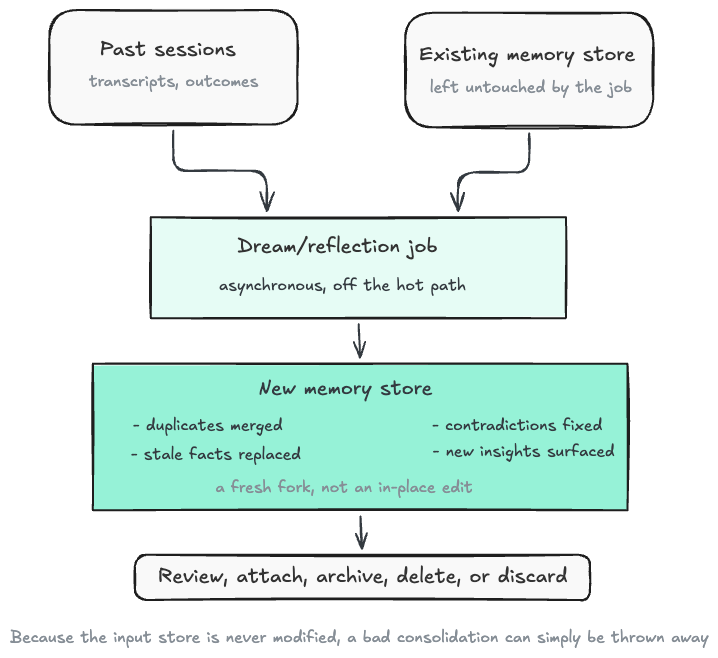
This pattern is important because it separates two jobs that are often confused.
Fast incremental write path
---------------------------
Capture useful information while the agent works.
Slow retrospective maintenance path
-----------------------------------
Review accumulated memory, clean it up, and consolidate it.
Those jobs have different requirements. The write path needs to be fast and local. The maintenance path can be slower, more global, and more reflective because it is not blocking the current user interaction.
This is very close to the way serious memory systems will need to work in production. You do not want every interaction to trigger an expensive global rewrite of memory, but you also do not want months of incremental writes to pile up without cleanup. Long-running agents need scheduled or event-triggered memory maintenance.
The broader architectural point is simple: memory is not only read and write. It also needs housekeeping.
Frontier 5: memory for action, not just recall
Many memory benchmarks ask whether a system can answer questions about past conversations. That is useful, but incomplete, because agents do not only answer questions. They act.
MemoryArena makes this distinction clear by testing agents across multi-session tasks where earlier actions and feedback matter later.
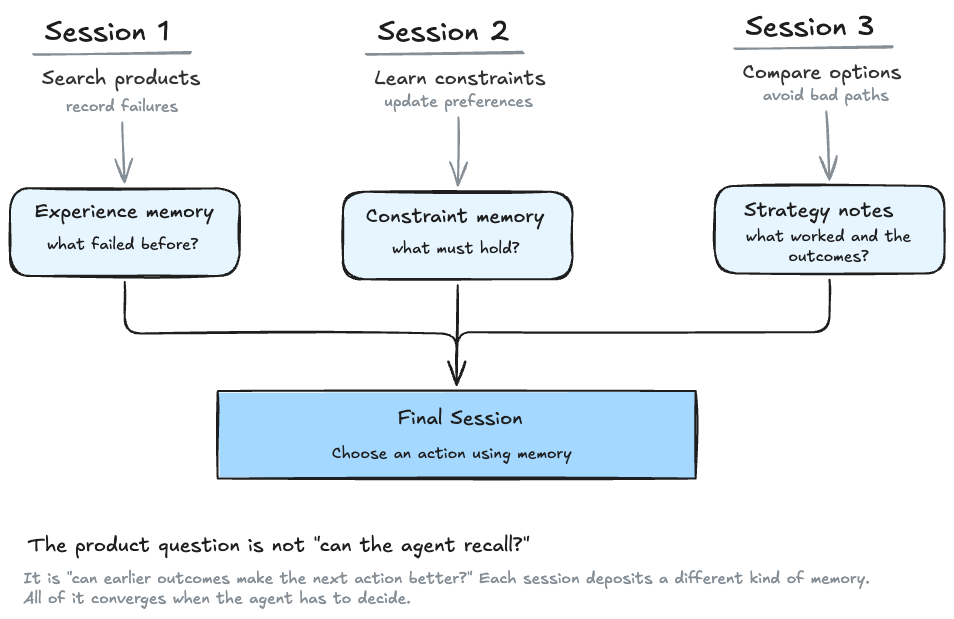
This matters because the product question is rarely, “Can the agent answer a memory question?” It is usually, “Can the agent use what happened earlier to behave better now?”
A coding agent should remember that one test command failed because an environment variable was missing. A web agent should remember that a previous form submission failed because one field is hidden behind an advanced section. A travel agent should remember that the user rejected a hotel not only because of price, but because it was too far from the station.
Those are experience memories. They are closer to procedural knowledge than ordinary facts, and they are central to long-horizon agents.
Frontier 6: memory at huge scale
BEAM tests conversations up to ten million tokens, and that scale breaks the fantasy that a large context window is enough. At this scale, memory usually needs multiple stores because each store serves a different purpose.
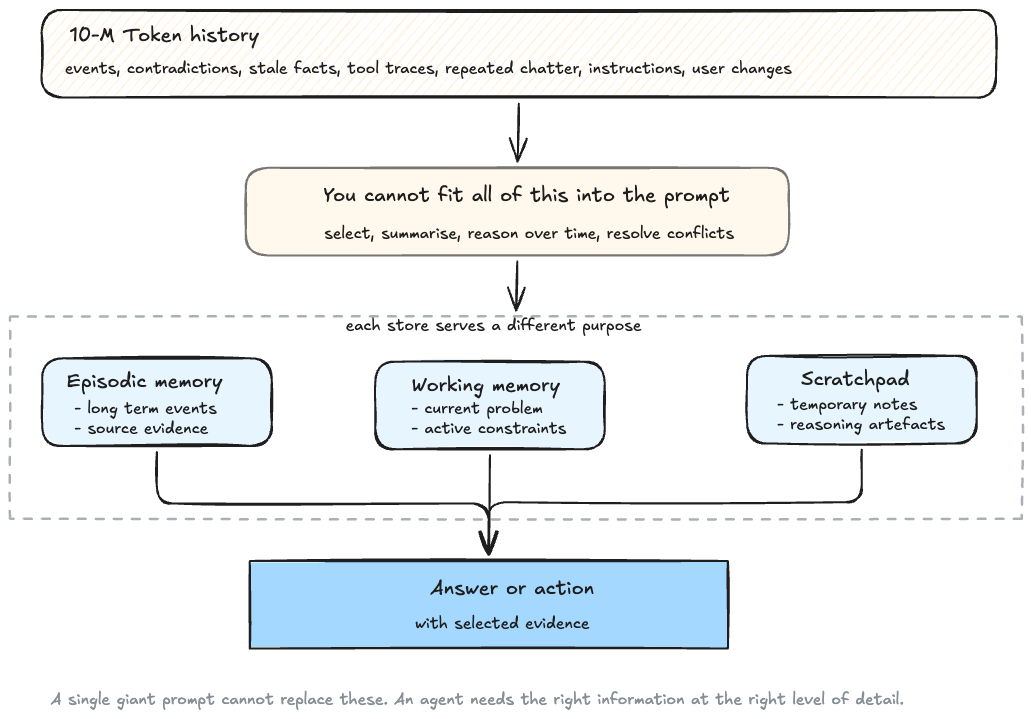
A single giant prompt cannot replace all of these because the agent needs the right information at the right abstraction level. Some tasks need exact evidence, some need summaries, some need current constraints, and some need temporary reasoning artifacts that should disappear after the task.
Frontier 7: multimodal and multi-agent memory
Agents increasingly see screens, read documents, browse websites, inspect code, use tools, and coordinate with other agents. Text-only memory will not be enough for those systems.
MIRIX and TeleMem point in this direction by organising memory across modalities and roles. One component may handle text, another may handle screenshots, another may track tool actions, and another may consolidate higher-level knowledge.
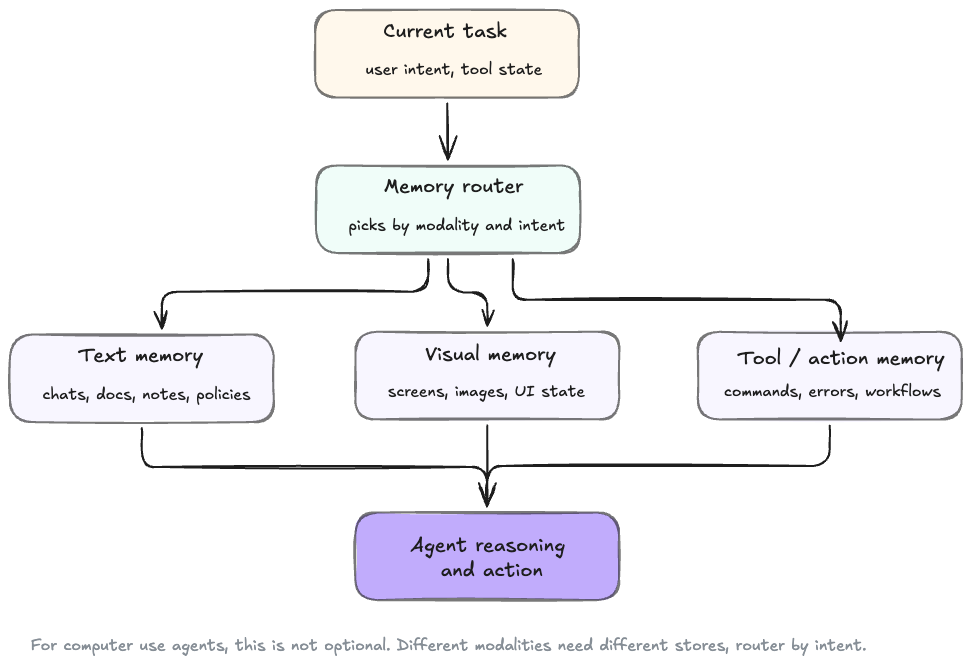
For computer-use agents, this is not optional. The agent may need to remember what the interface looked like, which sequence of clicks worked, which command failed, which file changed, and which explanation the user accepted.
The product decision tree
Before choosing a memory architecture, start with the product shape rather than the research leaderboard.
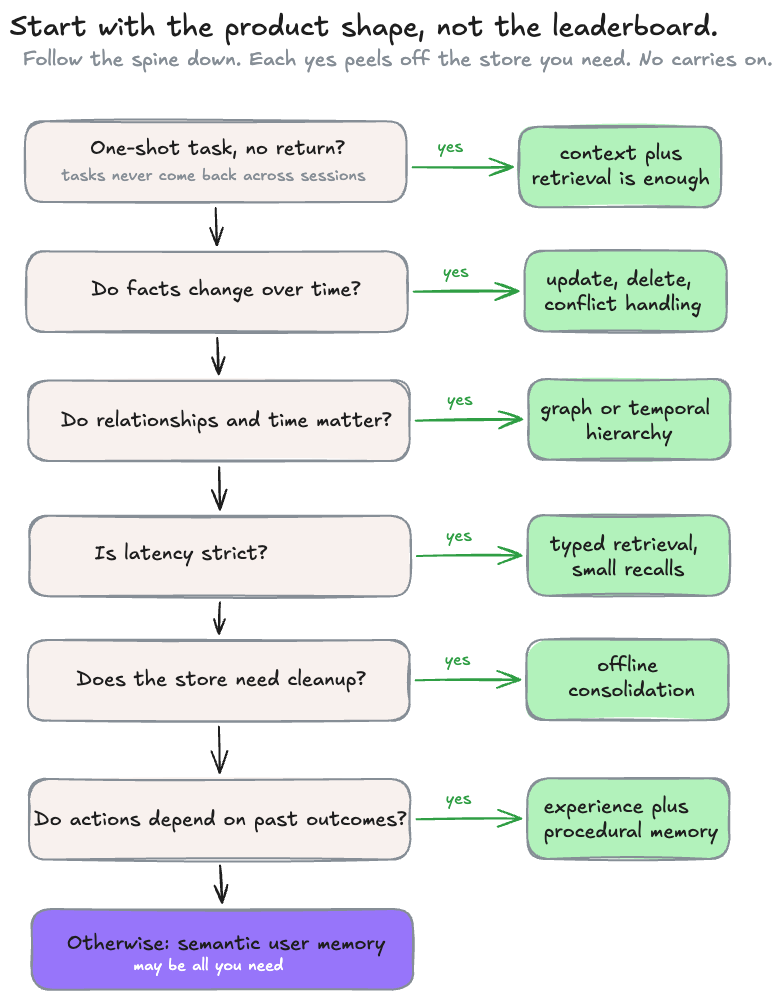
The decision should follow the failure mode. If the product fails because it forgets preferences, start with semantic user memory. If it fails because it repeats bad tool calls, add experience memory. If it fails because it cannot reason over time, add temporal structure. If it fails because memory gets cluttered, add maintenance and consolidation. If it fails because recall is slow, fix indexing before adding more intelligence.
The anti-patterns
A few traps show up repeatedly in real systems.
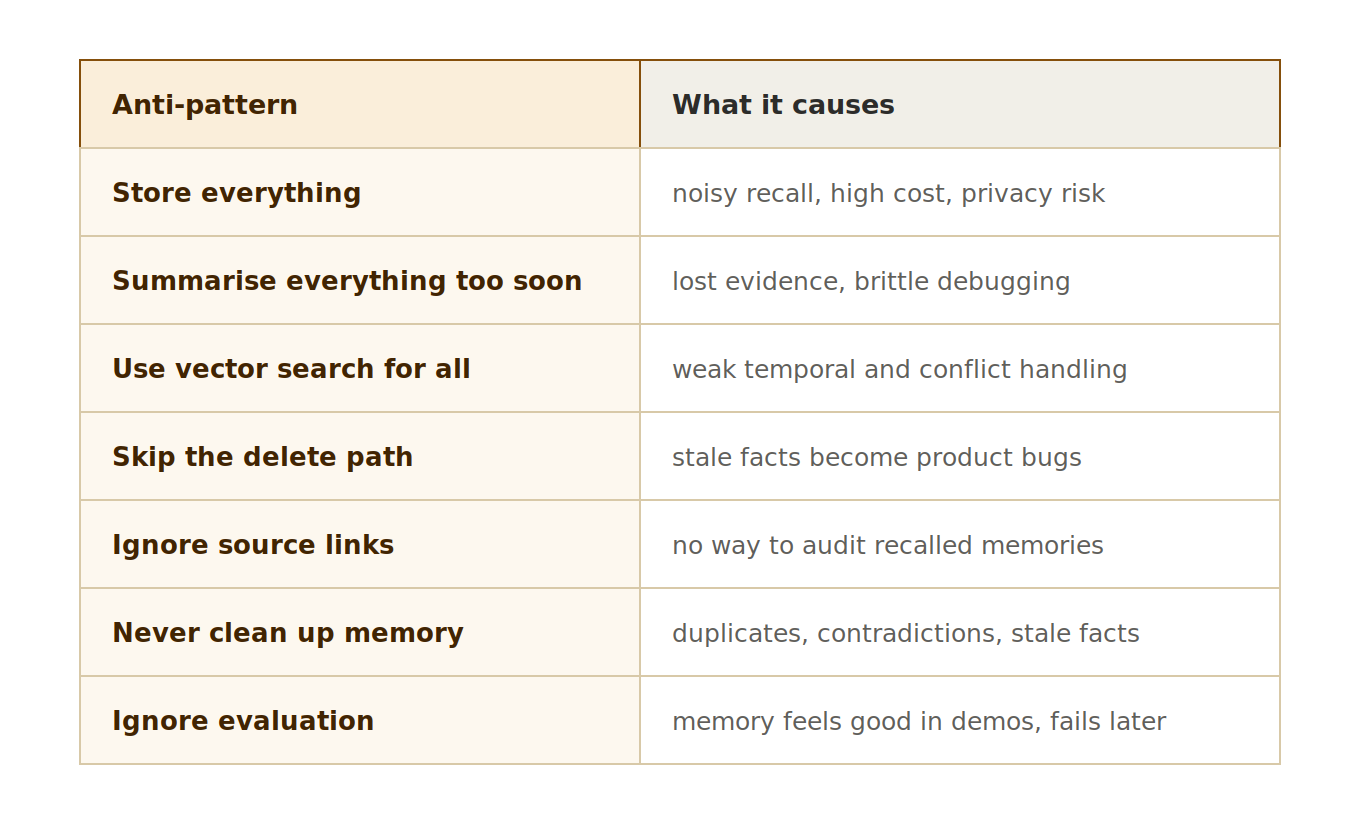
The biggest trap is treating memory as a feature you bolt on at the end. If the agent depends on continuity, then memory is part of the system architecture, not a plugin.
How to evaluate your own memory layer
Do not start with a public leaderboard. Start with the failures your product cannot afford.
Write down ten questions your agent should answer after a month of use.
What did the user correct last time?
Which workflow failed?
Which preference changed?
Which file matters for this task?
Which constraint is still active?
What should the agent avoid repeating?
What does the agent know only because of past tool use?
What needs to be forgotten?
What should be asked again because confidence is low?
What should be promoted from event to stable knowledge?
Then create a small evaluation set around those questions, with histories that include contradictions, stale facts, similar but irrelevant memories, and privacy-sensitive items that should not be recalled. Add maintenance tests too: does the system merge duplicates, resolve contradictions, and preserve source evidence after consolidation?
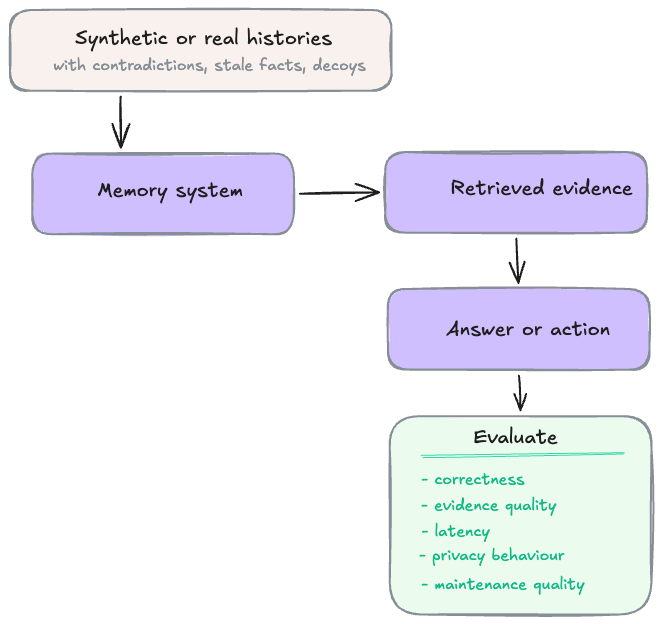
A memory system is only useful if it improves the product’s real behaviour while staying fast, inspectable, and safe.
What this means for builders
Agent memory is easy to underestimate because the first version looks simple: store a few facts, retrieve them later, and add them to the prompt.
But long-running agents put pressure on that simple model very quickly. Users change their minds. Facts go stale. Tool calls fail. Workflows evolve. Old assumptions stop being true. If the memory layer cannot keep up, the agent starts carrying the wrong context forward.
So the practical advice is simple: build memory as a lifecycle, not as a bucket.
Start with the smallest memory system that solves the real failure mode, but make sure the right seams exist from the beginning. Keep source evidence. Separate facts from beliefs. Track what changed. Design for deletion. Evaluate against the mistakes your product cannot afford. And add maintenance before accumulated memory becomes noise.
No spam, no sharing to third party. Only you and me.








Member discussion